*Camunda Platform 8, our cloud-native solution for process orchestration, launched in April 2022. Images and supporting documentation in this post may reflect an earlier version of our cloud and software solutions.
Do you need to integrate multiple components without the help of ACID (atomicity, consistency, isolation, and durability) transaction managers? Then, this blog post is for you.
I will first briefly explain what transaction managers are and why you might not have them at your disposal in modern architecture. I will also sketch a solution for how to work without transaction managers in general, but will also look at the project I know best as a concrete example: the Camunda workflow engine.
What’s a transaction manager?
You may know transactions from accessing relational databases. For example, in Java you could write (using Spring) the following code, using a relational database for payments and orders underneath:
@Transactional
public void paymentReceived(...) {
// ...
paymentRepository.save( payment );
orderService.markOrderPaid( payment.getOrderId(), payment.getId()
);
}Spring will make sure one transaction manager is used, which ensures one atomic operation. If there is any problem or exception, neither the payment is saved nor the order is marked as paid. This is also known as strong consistency, as on the database level you ensure the state is always consistent. There cannot be any order marked as paid where there is no payment saved in the database.
In Java, the Spring abstractions for transaction management are pretty common, so is Jakarta transactions (JTA). This allows you to use annotations to simply mark transaction boundaries, like @Transactional, @Required, @RequiresNew. Some more explanations about those can be found in the Java EE 6 JTA tutorial. This is a very convenient programming model, and as such, was considered a best practice for a decade of writing software.
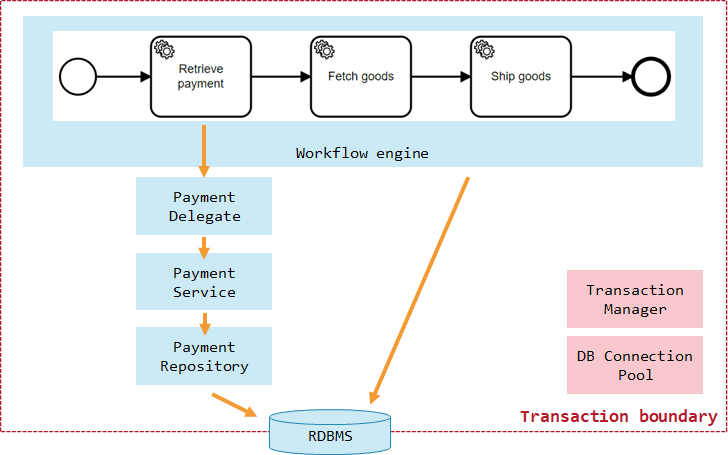
In the Camunda workflow engine (referring to version 7.x in this post), we also leverage transaction managers. Since you can run the workflow engine embedded as a library in your own application, it allows the following design (which is actually quite common amongst Camunda users): the workflow engine shares the database connection and transaction manager with the business logic. Some Java code (implemented as so-called JavaDelegates) was executed directly in the context of the workflow engine, invoking your business code, all via local method calls within one Java virtual machine (JVM).

This setup allows the workflow engine to join a common atomic transaction with the business logic. If anything in any component fails, everything is rolled back.
Do not rely on transaction managers too much!
This sounds like a great design, so why shouldn’t you rely on transaction managers too much in your system? The problem with transaction managers is that they only work well in one special case: you pinpoint everything to a single physical database.
As soon as you store workflow engine data in a separate database or you have separate databases for the payment microservice and the order fulfillment microservice, the transaction manager cannot leverage database transactions anymore. Then, the trouble starts. You might have heard otherwise by using distributed transactions and two-phase commits. However, those protocols should be considered not working. I want to spare you the details, but you can look into my talk, “Lost in transaction?” and specifically the paper, Life beyond Distributed Transactions: an Apostate’s Opinion if you are curious.
To summarize, you should assume that technical transactions cannot combine multiple distributed resources like two physical databases, a database and a messaging system, or simply two microservices.
Almost every system needs to leave that cozy place of just interacting with one physical database. Do you talk to some remote service via REST? No transaction manager will help you. Do you want to use Apache Kafka? No transaction manager. Do you send messages via AMQP? Well, you might have guessed, no transaction manager (if you stick to my statement above, that distributed transactions don’t work).
The point is, in modern architectures, I would consider having a transaction manager at your disposal a lucky exception. This means that you have to know the strategies to live without one anyway. The question is not if you will need those strategies, but where you apply them.
With that background, let’s go back to the Camunda example. Assume your payment logic is a separate microservice that is called via REST. Now, the picture looks different as you will run two separate technical transactions:

I will look into failure scenarios below, but due to recent discussions around the so-called external task pattern in Camunda, I want to make one further point. With external tasks, the workflow engine no longer directly invokes Java code. Instead, an own worker thread subscribes to work and executes it separately from the engine context. As we also encourage Camunda users to run a remote engine, communication is implemented via REST. The worker does not share the transaction with the workflow engine anymore, so the picture will look slightly different:

While this may appear more complicated, it really isn’t. Let’s examine this as we discuss the strategies to handle situations without transaction managers in the section below.
Living without a transaction manager
Every time you cross a transaction boundary, the transaction manager does not solve potential failure scenarios for you. This means you must handle those yourself as described below. Visit my talk on “3 common pitfalls in microservice integration and how to avoid them” for more details on these problems.

There are basically five possible failure scenarios when two components interact:
- Component A fails before it invokes the other component. Local rollback in component A. No problem.
- The (network) connection to component B fails and A gets an exception: local rollback in component A. It’s possible the connection might have succeeded and B might have committed some changes. Potential inconsistency.
- Component B fails: local rollback in B, exception is sent to A and leads to a rollback in A too. No problem.
- Connection problem while delivering the result to A: component A does not know what happened in B and needs to assume failure of B. Potential inconsistency.
- Component A received the result that B already committed, but cannot commit its local transaction because of problems. Inconsistency.
You can translate connection problems also to applications crashing in the wrong moment and will end up with the same scenarios. This is the reality you need to face. The great news is that solving those scenarios is actually not much of a problem in most cases. The most common strategy used is retrying and it leverages the so-called at-least once semantics.
Retrying and at-least once semantics
What this means is that whenever component A is in doubt about what just happened, it retries whatever it just did, until it gets a clear result that can also be committed locally. This is the only scenario where component A can be sure that B also did its work. This strategy ensures component B is called at least once; it can’t happen that it is never called without anybody noticing. It might actually be called multiple times. Because of the latter, component B must provide idempotency.
In the Camunda JavaDelegate example, this strategy can be easily applied. If a JavaDelegate calls a REST endpoint, it will retry this call until it successfully returns a result (which might also be an error message, but it must be a valid HTTP response that clearly indicates the state of the payment service). There is built-in functionality of the workflow engine.
Looking at the Camunda external task example, it can be applied in the same way, just on two levels. The external task worker will retry the REST call until it receives a proper response from the payment service and will forward that result to the workflow engine successfully. The only difference here is that network problems could occur on two connections, and crashes could happen in three components instead of two, but all of this does not actually change much. The design still makes sure the payment service will be called at least once. There is also built-in functionality in the workflow engine for retrying external tasks.
As a general rule of thumb, you will typically apply the at-least once semantic to most calls that leave your transaction boundary. This also means there are moments of inconsistency in every distributed system (e.g. because component B successfully committed something, but A does not know this yet). Moments of inconsistency are simply unavoidable in complex systems, and actually not so much of a problem when you are aware of this problem head-on. The term coined for this behavior is eventual consistency, and should actually be embraced in every architecture with a certain degree of complexity (but this is a theme for an own blog post).
One further remark here: providing reliable retries typically involves some form of persistence. This is something you get with Camunda automatically, but you could also leverage messaging (e.g. RabbitMQ or Apache Kafka) for this.
To summarize, eventual consistency, retrying, and at-least once semantics are concepts that are important to understand anyway.
Anecdotes from Jakarta EE
Ten years ago, I worked on a lot of projects leveraging JTA. One common problem we faced (and still regularly discuss amongst Camunda users) was the following: The workflow engine and some business logic (back then implemented as Enterprise Java Beans) share one transaction. Any component could mark the transaction as failed (“rollback only”). This is undoable. No component in the whole chain can commit anything afterwards, which is what you want with atomic operations.
However, there are situations where you still want to commit something. For example, you might want to handle certain errors by writing some business level logging, decrement retries in the workflow engine, or triggering error events in a BPMN process. You cannot do any of those things within the current transaction, as it is already marked for rollback.
The only way to get around this is to run a separate Enterprise Java Bean configured to open a separate translation (“requires new”). While this might be easy in your own code, you cannot easily get such behavior in a product like the Camunda workflow engine, which is built to operate in many different transactional scenarios.
Even if there are solutions to solve this, this scenario still shows a couple of things:
- You need to understand transactional behavior.
- Influencing transactional behavior gets hard if it is abstracted away from the developer.
- Failure situations can get hard to diagnose.
The lesson to learn here is not to share transaction managers between components but to tackle potential pitfalls head-on. Embracing eventual consistency might be better than relying on transaction managers.
Further reading
To dive deeper into transactions and eventual consistency, I also recommend diving into advanced strategies to handle inconsistencies on the business level. For example, read chapter nine of Practical Process Automation, and review the saga pattern as it is especially interesting. It demonstrates that a lot of consistency decisions should actually be elevated to the business level. As a developer, you can hardly decide how bad it is to mark orders as paid, even if the payment failed. Just assume you sell cheap online subscriptions. Maybe your business is much better off to accept a missing payment once in a while instead of investing in an engineering effort to avoid such situations?
Conclusion
In this post, I showed that eventual consistency (especially retries) and at-least once semantics are important concepts to know. They allow you to integrate multiple components, even beyond the scope of what a transaction manager can handle, which is limited to one physical database.
Once applied, those strategies enable you to make more flexible decisions in your architecture, like using multiple resources or technologies. For example, you could see that once you call a REST service, it doesn’t even matter if a workflow engine like Camunda is used remotely.


