One of the most wonderful things we experienced while building Camunda Platform 8 was being able to make fundamental redesigns to avoid some of the challenges present in Camunda Platform 7. This post explains how we managed to remove the long despised, and often unavoidable, OptimisticLockingException error in Camunda Platform 7 by redesigning the core of the process engine. In addition, we’ll share how removing the potential for that error exponentially increased the performance of Camunda Platform 8’s engine when compared to Camunda Platform 7.
Why Does an OptimisticLockingException Happen?
The Camunda Platform 7 process engine has some rules that exist to ensure a consistent state is maintained for your process. One of those rules is that only one thread is permitted to change the state at any given time. That can mean updating process variables, completing a task or moving a token through a gateway. Basically, anything that might involve changing the current state of the process. If two different systems or people are trying to make a change at the same time, one of them will succeed and the other will see something like this:
ENGINE-14006 Exception while executing job 51559:
OptimisticLockingException. To see the full stacktrace set logging level to DEBUGThis means that the user needs to try again later. Of course, this is going to slow things down, but it’s also going to guarantee that there is a safe consistent state. It seems like a fair trade.
What Are the Consequences of this Approach?
The most consequential aspect of this approach is when you’re using the external task pattern, and have parallel tasks or branches in your BPMN model.


The two examples above are a multi-instance service task and a parallel gateway followed by two or more service tasks. What these two patterns have in common is that each instance of the task is independently executed by an external service that will then tell the engine that the task is complete. If two external services come back at the same time, one will be able to perform the complete action on the task while the other one will get an error. This is because only one action that changes the state can happen at any given time for a single process instance. This is quite a limitation for high throughput systems.
Setting Up the Experiment
So let’s get out of the theoretical aspects of this topic and discuss this with some cold hard facts. We’re going to run an experiment where we’ve created a process model with a parallel multi-instance task. There will be 300 instances of this task that need to be completed and we’ll run some experiments that should demonstrate the complications of scaling for this. It’s important to remember that the 300 tasks will be created in parallel with a single database update, and it’s going to be all about how quickly we can go from 300 tasks waiting to be completed to zero.

Both Camunda Platform 7 and Camunda Platform 8 will run the same model, and for each experiment, we’ll be using the same worker settings. I’ll even be running both workers locally on my lovely little computer. The main difference is that I’ll be running Camunda Platform 7 locally, while I’m crossing into the big bad world of the internet to connect with Camunda Platform 8 SaaS.
Experiment one
We’ve created a single task worker written in Java that’ll only fetch one job at a time, and then complete it with a test variable. We can do that by changing the maxTask configuration of the worker’s application.yml, ensuring the worker makes a call that specifically asks for one task at a time. This should be the slowest way to execute the tasks as it’s basically running them sequentially. I’ll first run this with Camunda Platform 7 and see what the results look like.
One very nice thing about using Camunda is that I can use Camunda Optimize to easily visualize the results.

What we’re seeing in the results is that completing the fastest task took about a second, but the slowest one took more than a minute and a half. Since we’re completing all of these sequentially, the average time works out to being a little under a minute.
How does Camunda Platform 8 compete with the same settings? Well, Optimize also works with Camunda Platform 8, so it’s also pretty easy to see.

It looks like the numbers are slightly better but nothing to write home about. Of course, we’re not really trying any parallel execution with this experiment—this should really be considered the benchmark.
The final scores for one worker with one task fetched per request is:
Time to Complete TaskCamunda Platform 7Camunda Platform 8Min Duration1s 788ms32sMax Duration1min 40s 42ms51s 437msAverage Duration51s 425ms42s 18msMedian Duration51s 550ms42s 200ms
It’s a strange anomaly that the minimum duration for Camunda Platform 8 comes to an oddly long 32 seconds, this could be due to network verifications and one-off security checks (I never did work out why exactly). Eventually, we’ll see in some of the follow-up experiments that this outlier disappears.
Experiment two
With the same setup as before, there are 300 tasks all ready to go, but now we’re going to change how many tasks will be fetched by the worker. We’re going to fetch 10 at a time, instead of one, by updating the settings of the workers for both Camunda Platform 7 and Camunda Platform 8.
After 300 tasks have been completed in Camunda Platform 7, here’s what Optimize had to say about it.

Well at first, it may seem like I put the wrong image on this part of the post, but actually we’re already starting to see the Optimistic Lock error wreak some havoc. What’s going on here is that we’re seeing a massive increase in wait times. This is because we’re trying to complete a bunch of jobs in parallel. Some will be completed without a problem, and others will fail to complete and then just wait for a short time before retrying it — leading to much longer average wait times.
What about Camunda Platform 8? Well, it’s a very different story.

This is far more like it. We scaled up to 10 jobs at a time, and we’ve gone from an average of 42 seconds to just three. With Camunda Platform 7, of course, things played out very differently, where adding more jobs did some real damage going from 51 milliseconds to more than two minutes on average.
It’s clear that Camunda Platform 8 is performing much better than Camunda Platform 7, but what about what’s under the hood? Well, Camunda Platform 8 doesn’t operate under the same single-threaded principles, so there’s not going to be any optimistic locking errors to worry about. Instead, the engine works on a “single writer principle” where each event is written to an append-only log, which will then progress the state of the process.
The final scores for one worker with ten tasks fetched per request are:
Time to Complete TaskCamunda Platform 7Camunda Platform 8Min Duration636ms400msMax Duration10mins 3s 994ms3s 669msAverage Duration2mins 46s 688ms2s 71msMedian Duration2mins 31s2s 159ms
Experiment three
Once again, our 300 tasks are going to wait for their time to be completed, and now we’re going to run two workers independently with each one fetching 10 tasks at a time. We’ll start the experiment with Camunda Platform 7. Having two workers picking up bigger batches should hopefully lead to less contention and maybe fewer synchronization problems.

Often, doubling the number of workers on a finite number of work items would get the job done faster, but this is not the case. We can clearly see that there really is an obvious plateau for dealing with parallel tasks, and really no practical way to scale it while maintaining a consistent state that the optimistic locking mechanism provides.
Without needing to rely on optimistic locking to maintain consistency, Camunda Platform 8 performs a lot better.

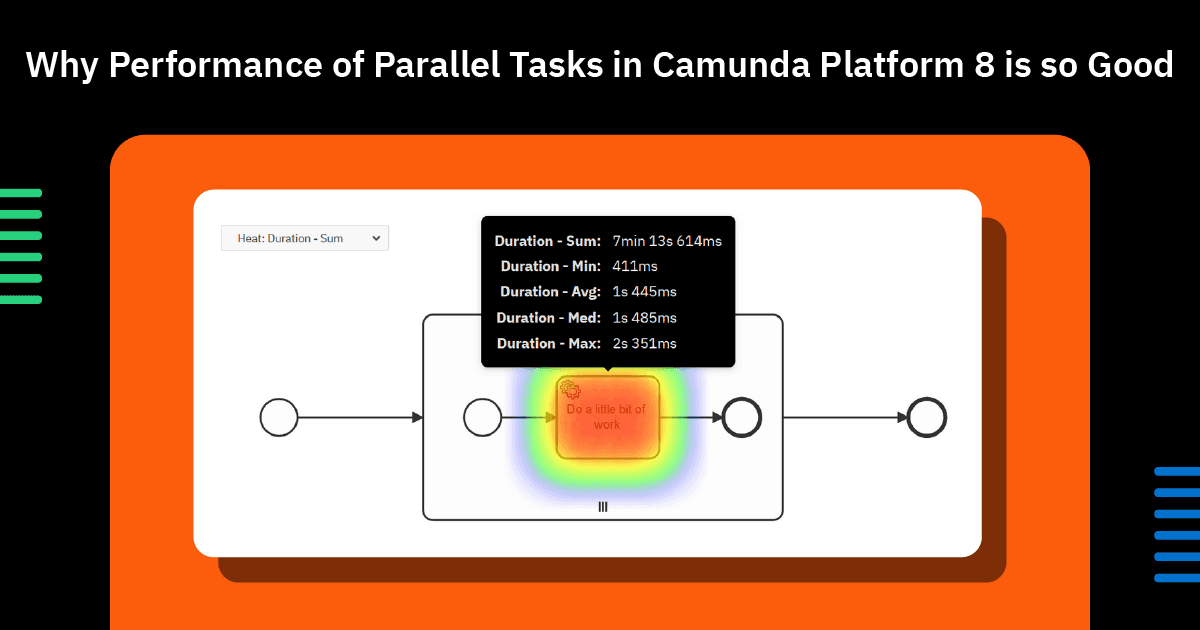
Now, we have a wonderful result. Every number has been brought down and is getting closer to only being limited by the length of time it takes to complete a single item – which is exactly what you’d want to see from a fully horizontally scalable system.
The final scores for two workers with ten tasks fetched per request is:
Time to Complete TaskCamunda Platform 7Camunda Platform 8Min Duration636ms411msMax Duration10mins 3s 994ms2s 351msAverage Duration2mins 46s 688ms1s 445msMedian Duration2mins 31ms1s 485ms
Wrap Up
I think there are two important points to draw from this post. The first and most obvious one is that Camunda Platform 8 is designed from the ground up to scale in ways that Camunda Platform 7 never was. For me, an even more important takeaway is to understand why Camunda Platform 8 is better on a more meta level. Camunda has been tuning and perfecting Camunda Platform 7 for more than eight years now. With Camunda Platform 8, we’re re-imagining a workflow engine with all the experience and knowledge we’ve gained over that time. Developing Camunda Platform 8 has been really exciting. This blog post is the answer to a conversation that started with, “Optimistic locking stops us from scaling. If we could redesign an engine without it – what would that look like ?” Well, it looks like Camunda Platform 8.
If you want to run this benchmark by yourself, I’ll soon be sharing a GitHub repository with the code I used.


