We recently shared 3 Common Pitfalls in Microservice Integration – and how to avoid them and lots of you wanted more. So this four-part blog series takes us one step back to the things you’ll be considering before migrating to a microservices architecture and applying workflow automation. In this third post in the series, we’ll dive deeper into architecture and discuss whether it’s better to run a workflow engine centralized or decentralized.
You can find the source code on GitHub for the simple order fulfillment application, introduced in the first blog in this series, available as the flowing-retail sample application which we use as an example in this blog.
Central or decentralized workflow engine?
If you want to use the workflow engine for work distribution – like we discussed in the second blog of this series – , it has to be centralized. In the other alternatives you have two and a half options:
- Decentralized engines, meaning you run one engine per microservice
- One central engine which serves multiple microservices
- A central engine, that is used like decentralized ones.
A good background read on this is Architecture options to run a workflow engine.

Decentralized engines
With microservices, the default is to give teams a lot of autonomy and isolate them from each other as much as possible. In this sense, it is also the default to have decentralized engines, one workflow engine per microservice that needs one. Every team can probably even decide which actual engine (product) they want to use.
- Implementation example: https://github.com/berndruecker/flowing-retail/tree/master/kafka/java/order-zeebe/
- Pro: Autonomy; isolation.
- Con: Every team has to operate its own engine (including e.g. patching); no central monitoring out-of-the-box (yet).
Typically monitoring is discussed most in this architecture: “How can we keep an overview of what is going on”?
It is most often an advantage to have decentralized operating tools. As teams in microservice architectures often do DevOps for the services they run, they are responsible for fixing errors in workflows. So it is pretty cool that they have a focused view where they only see things they are responsible for.
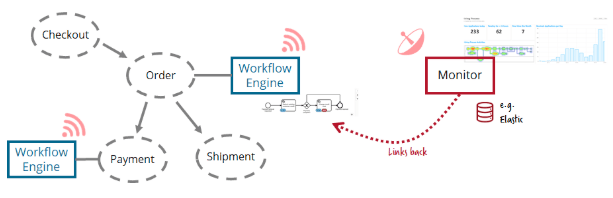
Central monitoring with decentralized engines
But often you still want to have a general overview, at least of end-to-end flows crossing microservice boundaries. Customers often build their own centralized monitoring, most often based on e.g. Elastic.
You can now send the most important events from the decentralized engines (e.g. workflow instance started, milestone reached, workflow instance failed or ended) to it. The central monitoring just shows the overview on a higher level and links back to the decentralized operating tools for details. In other words, the decentralized workflow engine handles all retry and failure handling logic and the central monitoring simply gives visibility into the overall flow.

In our own stack we allow certain tools to collect data from decentralized engines, e.g. Camunda Optimize.
- Implementation example: A simplified example is contained in https://github.com/berndruecker/flowing-retail/tree/master/kafka/java/monitor
One Central Engine
To simplify operations, you can also run a central engine. This is a remote resource that microservices can connect to in order to deploy and execute workflows. Technically that might be via REST (Camunda BPM) or gRPC (Zeebe). Of course you could also leverage Camunda Cloud as a managed workflow engine.

- Implementation example: https://github.com/berndruecker/flowing-retail/tree/master/kafka/java/order-zeebe
- Pro: Ease of operations; central monitoring available out-of-the-box
- Con: Less strict isolation between the microservices, in terms of runtime data but also in terms of product versions; central component is more critical in terms of availability requirements.
If you want to use the workflow engine as work distribution you need to run it centralized.
Central Engine, that is used like a Decentralized Engine.
This approach requires explanation. What you can do in Camunda is to run the workflow engine as a library (e.g. using the Spring Boot Starter) in a decentralized manner in different microservices. But you then connect all of these engines to a central database where they meet. This allows you to have central monitoring for free.

- Pro: Central monitoring available out-of-the-box.
- Con: Less isolation between the microservices in terms of runtime data but also in terms of product versions, but actually moderated by features like Rolling Upgrade and Deployment Aware Process Engine.
Thoughts and recommendation
I personally tend to favor the decentralized approach in general. It is simply in sync with the microservice values.
However, I’m fine with running a central engine for the right reasons. This is especially true for smaller companies where operations overhead matters more than clear communication boundaries. It is also less of a problem to coordinate a maintenance window for the workflow engine in these situations. So as a rule of thumb: the bigger the company is, the more you should tend towards decentralization. On top of organizational reasons, the load on an engine could also make the decision clear —as multiple engines also mean to distribute load.
Having the hybrid with a shared database is a neat trick possible with Camunda, but should probably not be overused. I would also limit it to scenarios where you can still oversee all use cases of the workflow engine and easily talk to each team using it.
Of course, you can also mix and match. For example, you could share one database between a limited number of microservices, that are somehow related, but other teams use a completely separated engine.
However, a much more important question than where the engine itself runs is about ownership and governance of the process models – which is exactly what we’ll be discussing in the fourth and final installment of this blog series!
This blog was originally published on Bernd’s blog – check it out if you want to dive even deeper into microservices!


