This article focuses on file handling in processes, the hurdles to take, and how a Camunda Connector can help you to automate your file intensive processes.
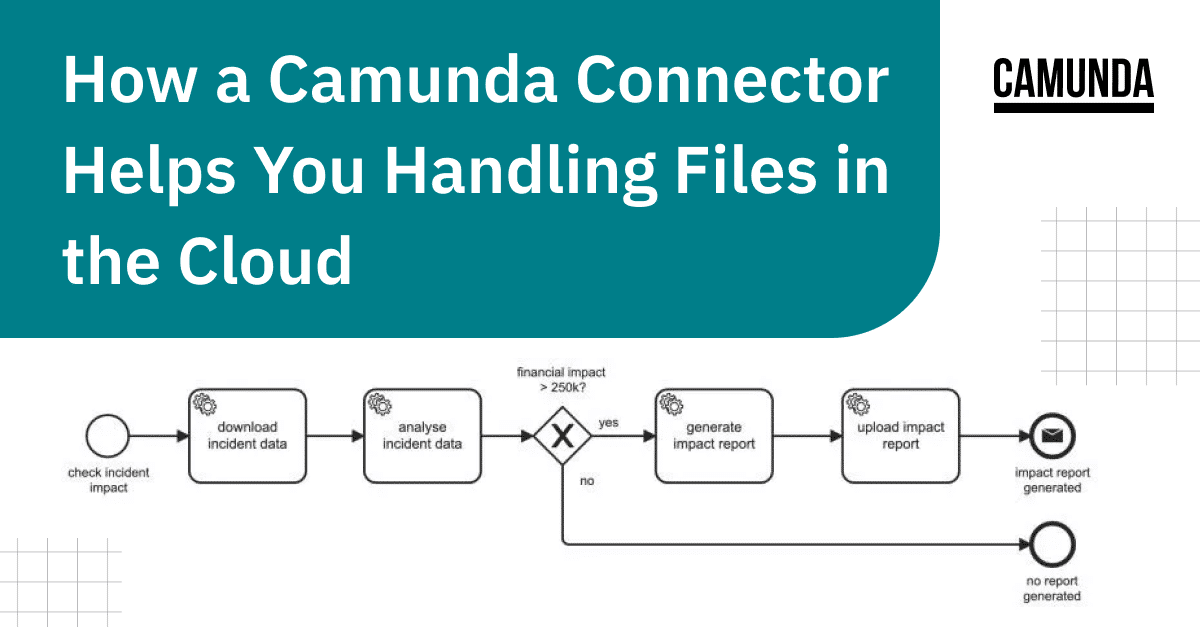
The following example shows a process that downloads a file from cloud storage, analyses the data, and generates a report based on the contents. Afterwards it uploads the report back to the cloud storage. The process uses data from a file to decide how to continue its flow.

What you will learn from this article:
- The limitations of the various Camunda engine setups when handling files
- The reasons why putting files into process variables is bad practice
- The details on how using a Connector makes it easier and more maintainable to handle files
Independent from the underlying architecture of the process engine, you should always ask yourself if it is a good idea putting whole files into the process engine. With simple data used to drive your process forward—e.g., for decisions—this is easy, since you just set them as process variables. But files on the other hand come with a certain overhead: they have metadata attached to them, and they can be quite big. So it is generally not a good idea to send them to the process engine as variables to drive your process forward.
Why is file handling not trivial?
With Camunda 7, developers are able to embed the engine into their process application. With the provided Java API, there are very fine granular options to interact with the engine and the processes deployed to it. Business objects can be serialized in many ways and sent to the engine where they could be retrieved and deserialized by other activities with relatively low overhead. The biggest drawback is that the payload ends up in the database as blobs (binary large objects) taking up space in the engine’s database runtime table and also in the history table of your Camunda instance.

This gets more complicated when you want to run Camunda 7 as a remote engine with an external task client. This scenario might be necessary when using a programming language that is not supported out of the box, or running a central Camunda installation. This means switching out the Java API and instead using the engine’s REST API to communicate with the engine, transforming your application into a distributed system where networking plays an important role. Sending a payload over a network to the engine is now a relevant factor adding to the equation, especially if the payload contains big files.

With the introduction of Camunda 8, a remote engine called Zeebe is now the standard, removing the possibility to embed an engine and additionally leveraging the advantages of a distributed system, e.g. to improve fault-tolerance and scalability. The process engine consists of a set of independent nodes, each one capable of handling the execution of process instances of the processes deployed to them. For fault-tolerance, all the data is replicated between the nodes, including process variables. The communication with the cluster is implemented using gRPC (Google Remote Procedure Call).

Camunda 8 introduces some limitations that have to be taken into account when trying to add files to variables: engine and infrastructure limitations.
Zeebe—the engine behind Camunda 8—only supports variables in JSON format, with a maximum size of approximately 3 MB. You could add the content of your file as a character string to the payload if it is relatively small.
Now your file is in the engine’s process state. What happens next is that Zeebe replicates the context based on the replication factor to some of the other brokers to assure fault tolerance, so now you have multiplied your file size by the factor of the replication. Additionally the engine sends the data to Operate for runtime access and Optimize for process optimization, adding two more copies. This takes away disk space from your cluster and has an impact on the overall performance of the nodes, be it self-managed or the SaaS offering by Camunda.
The underlying storage of a partition has a compaction and cleanup mechanism, but depending on the load you might reach performance limitations before a cleanup is triggered. You can read more about the fundamentals in Camunda’s documents about resource planning and about Facebook’s RocksDB in its official documentation.
What is the alternative to sending files to the engine?
In the previous section, I told you about the disadvantages of storing files into variables. The alternative would be to store the file locally and only hand over the reference to the file. But this approach is also not free from obstacles. Generally there is no difference between Camunda 7 and 8; for example, you can use a simple FileOutputStream in your worker or delegate to write your file to the local disk and return the file handle itself.
Path file = baseDir.resolve(filePath);
try (OutputStream stream = Files.newOutputStream(file)) {
stream.write(content);
return file;
}Now you can hand the path as a variable to the engine and let other activities access it. This also works if you want to access this file from another process, because Camunda allows you to hand over variables during a process start as well.
But what happens if your dependent process doesn’t share the local file system of your process application? You need a central place to put your file and share the path. This allows you to keep files locally to share them between activities and store them globally (e.g., in the cloud) to access them between processes, without the need of a shared file system.

What are the advantages of using a Connector?
There are many good reasons to use a Connector in your project. The important ones being:
- Open-source
- Accessibility through the marketplace
- Reusability
The most compelling one is the open-source and community nature behind a Camunda Connector. You can see the code in GitHub and create a pull request with changes or even your own fork of the repository. Even if the project is no longer maintained, you have access to the sources.
Another advantage is accessibility through the Marketplace. Customers can search for certain functionalities and add the Connector to their processes. The only downside is that partner and community Connectors cannot be added directly to the SaaS solution. You have to deploy and run them yourself.
Another advantage is that the Connector and its runtime can easily be reused between different processes and applications in your company. You don’t need to reinvent the wheel every time you need some special kind of logic. Packing it into a Connector makes it available for other teams in your company and provides a unified configuration interface in the Camunda Modeler. The AWS S3 Connector, for example, only needs two configurations: authentication for AWS and the location of the file. The rest is handled by the Connector.
What features does the AWS S3 Connector provide?
Currently the Connector provides these main features to support better file handling:
- Simple configuration interface for AWS authentication and file location
- CRUD operations in Amazon S3 buckets
- Location sharing with result variables
- High quality standards
With this set, we can already implement most of the main scenarios when handling files: we can, for example, download an input file, parse it, and use the content to do some processing. The downloaded files are shared in the local file system and the location is returned by the Connector. If you decide to generate a result, you can also save it locally and upload it back to the cloud, since our file handling APIs are accessible for Connectors and even a JobWorker (or a JavaDelegate) running in the same application.
Another process can react to that upload by listening for events on the bucket via the existing Amazon Simple Notification Service (SNS) inbound Connector by Camunda and do some processing on that file as well. Additionally, the AWS S3 Connector is implemented and tested on the highest standards, the same as if we would implement it for a paying customer. This makes it easy for customers to focus on the functionality and not worry about quality and reliability in production.
Interested in using it? You can find the Connector in the Camunda Marketplace for Connectors and the source code in the GitHub repository.
Editor’s note: This post originally appeared on Medium here.


