
On April 24, 2019, we hosted our first-ever Operate webinar, sharing background on the problem that Operate seeks to solve and demoing a few of its core capabilities.
A recording of the webinar has been uploaded, and you can find it here.
We’d also like to put together answers to questions that came in during the webinar, including some that we didn’t have an opportunity to answer during the webinar itself.
In some cases, we edited the wording of the questions for clarity–we want to make sure that someone coming to this post without the context of the webinar can follow what we’re talking about–and we also combined questions that were similar into a single topic.
How does Operate handle Zeebe running as a cluster, where exported data would be coming from multiple Zeebe partitions?
The Zeebe Elasticsearch exporter sends data to a single Elasticsearch instance (even if that data is coming from multiple Zeebe partitions), then Operate reads data from that single Elasticsearch instance. So there’s no additional configuration required by the user to work with Operate when Zeebe’s running as a cluster.
How is it possible to connect data stores / databases to Zeebe?
One point of clarification: Zeebe doesn’t require a database for managing the state of running workflow instances. That state is stored directly on the same machines where Zeebe is deployed.
But Zeebe doesn’t store historic workflow data, and it’s necessary to use an external storage system for this. Zeebe’s exporter interface (described here in the documentation) makes it possible to export data to a system of your choice.
The Zeebe distro includes a ready-to-go Elasticsearch exporter (the same exporter used to get data to Operate) and there are also a community-contributed exporters listed on the Awesome Zeebe page.
Does Operate require its own dedicated Elasticsearch instance, or could you reuse an existing one?
Operate does not require its own dedicated Elasticsearch instance. If using an existing instance with an index or indices that contains data unrelated to Zeebe, it’s important to be aware of how indices are named to avoid naming conflicts.
Currently, Operate uses an “operate” prefix for all index names by default. This prefix can be reconfigured via the configuration parameter camunda.operate.elasticsearch.indexPrefix .
Can Zeebe and Operate get “out of sync”? If so, can this cause any issues?
It is possible that the state of Zeebe and Operate can be temporarily out of sync. Imagine a scenario where a user cancels a workflow instance in Operate (thus sending a cancel command to Zeebe). The workflow instance in Zeebe is canceled almost immediately, but there is lag between the cancellation of the instance in Zeebe and the relevant event being exported to Elasticsearch from Zeebe and imported by Operate. And so for some period of time, Operate does not yet show the cancelled instance as cancelled.
This syncing issue won’t cause any problems with workflow execution in Zeebe. If, for example, the user tries to cancel the instance again after it’s already been cancelled in Zeebe, but the instance is not yet showing as canceled in Operate, there’ll be an exception in the logs (e.g. io.grpc.StatusRuntimeException: NOT_FOUND: Command rejected with code ‘CANCEL’: Expected to cancel a workflow instance with key ‘1’, but no such workflow was found), but neither Zeebe’s processing nor use of Operate will be interrupted.
This lag could cause confusion with Operate users, though, so we’ll be thinking of how to best communicate to the user what’s happening in the Operate UI.
When retrying instances in batch, is it possible for Operate to “throttle” retries so not to overload the service responsible for them?
This is actually something that can be handled in the Zeebe client rather than in Operate. The Zeebe client includes a maxJobsToActivate parameter that defines the maximum number of jobs that will be activated in a single request, thus providing a degree of control on load on the service that will be handling the batch retry. You can read more about this client configuration here.
Is Operate available on Docker?
Yes:
- There’s a Camunda Operate Docker image available here: https://hub.docker.com/r/camunda/operate
- There’s a docker-compose for Zeebe and Operate available here: https://github.com/jwulf/zeebe-operate-docker
We saw how to initiate a batch retry of workflow instances, but is there a way to write a script to perform a batch update to, for example, add a missing variable to many workflow instances?
There’s no feature like this in Operate right now, but we agree it would be valuable and is something we have discussed in the past. It’ll be on our radar as we plan the future roadmap.
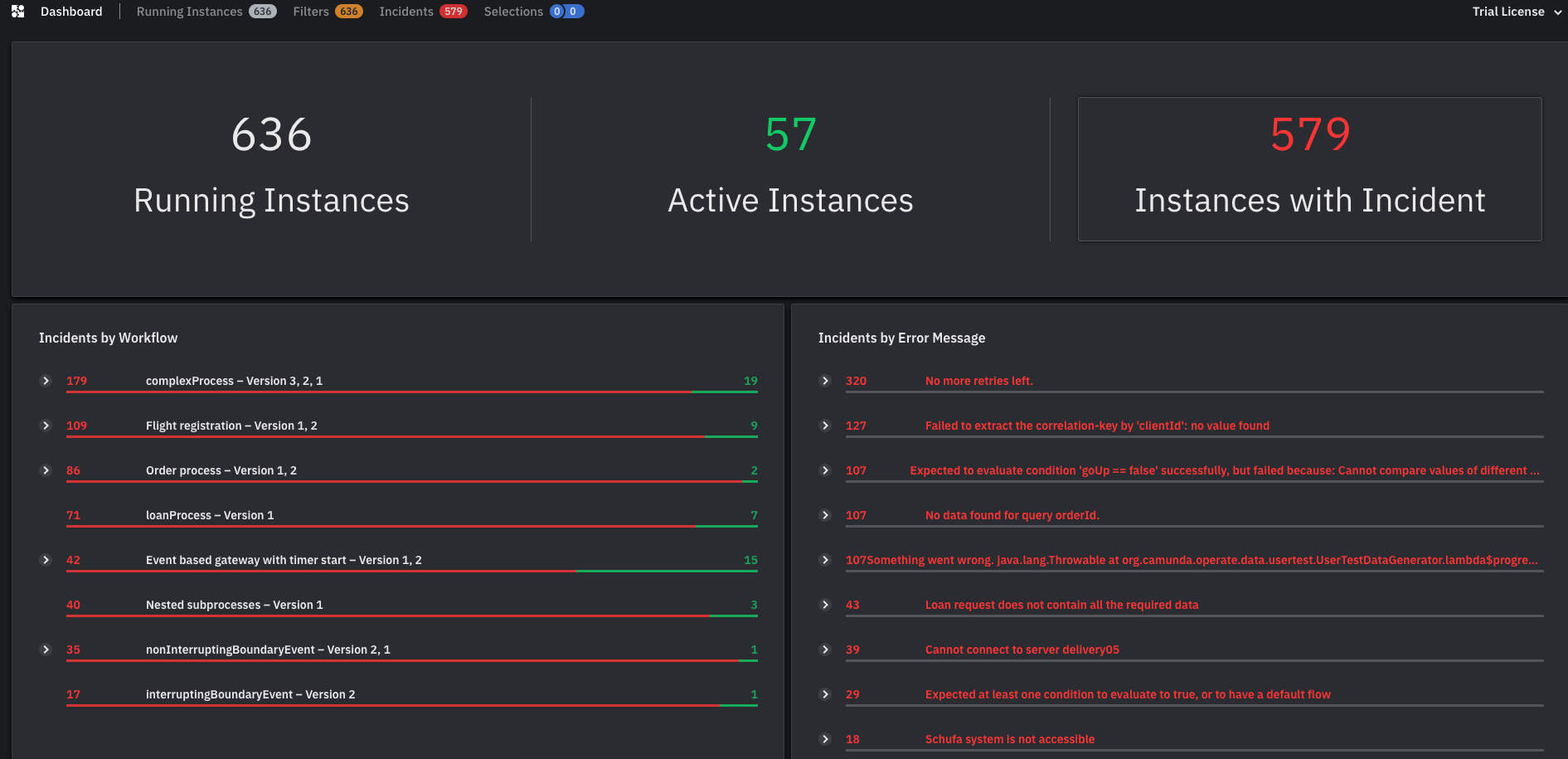
Is there a way to parse incidents by error message to help detect if e.g. there’s a widespread issue affecting a service?
The Operate home screen does include a grouping of incidents by error message–below is a screenshot with some demo data from our staging environment–but it doesn’t allow you to do any filtering by “similar” error messages. This is also something we agree would be valuable and will discuss in the future.
What’s the plan for how Operate will be licensed?
Here’s an overview of the current plan for Operate licensing:
- At some point in the future (likely late 2019 or early 2020), we plan to offer a Zeebe “enterprise edition” that will include:
- Operate with a license that allows for production use
- The open-source Zeebe engine
- Services and support
- We will continue to provide Operate for free and unrestricted non-production use so that it can be used in Getting Started tutorials and proofs of concept. As of now, we do not plan to offer an open-source or “community” version of Operate that can be used in production and includes only a subset of features.
- We do want also to be sure that a user can take Zeebe into production and run it confidently using only open-source components and without paying for any enterprise software. That’s a large part of the reason we included an Elasticsearch exporter as part of the core Zeebe distribution–Kibana then provides a way to build a dashboard for monitoring and analyzing workflow instances that are running in Zeebe.
- We are open for feedback about how we can improve the Elasticsearch exporter to make Kibana more useful, and we are also open for ideas of other open-source systems that Zeebe could integrate with to provide similar visibility / analytics capabilities.