*Camunda Platform 8, our cloud-native solution for process orchestration, launched in April 2022. Images and supporting documentation in this post may reflect an earlier version of our cloud and software solutions.
Jenkins is a battle-tested software with a sophisticated ecosystem that allows it to deal with almost any use case. Simply put, it’s the Swiss army knife of the CI/CD.
In August 2021, we published our story about how we built a CI pipeline that fits our advanced and unique use case. We shared a high-level overview of our challenges while building advanced declarative pipelines for our workflow and decision engine. Today, we dive more into the technical details and implementation in this post. (Hint: You can download and use the code in your pipeline.)
Background
Let’s take a step back and understand why we moved to the declarative pipelines in the first place. We have an advanced CI pipeline for Camunda Platform 7. Camunda Platform 7 is an open, enterprise project with a complex CI. The core engine works with nine different databases, six application servers, seven different Java versions in addition to many tests, including unit, integration, end-to-end. Also, the CI setup needs to support six previous versions of the core engine. That translates to about 400 jobs per single Camunda Platform 7 version.
With that gigantic CI, in the past, we used Jenkins Job DSL with a lot of homemade Groovy code to template the jobs in an upstream-downstream style (a chain of jobs where each job triggers another job till the chain ends). Jenkins Job DSL is so powerful. However, we had a steep learning curve with that setup, and it’s hard to onboard developers to manage and maintain the CI without significant support from our DevOps engineers. Also, the upstream-downstream job chain has some limitations; there was no end-to-end visualization of the CI jobs, which makes it hard to identify the CI build time and many other things. You can find more details about that in the Jenkins Is The Way post.
Goal
So we asked ourselves, “How can we improve this situation?” We prioritized improving the CI experience to empower the developers using it.
Challenges
In order to migrate those 400 Jenkins DSL freestyle jobs, that work in upstream-downstream style, to the more standard and straightforward syntax of Jenkins declarative pipelines (Jenkinsfiles), we had two main challenges:
- Our CI has many jobs that we’ll convert as stages in the Jenkins declarative pipeline. Instead of using a single Jenkinsfile, we split the stages among a couple of Jenkinsfiles.
- Jenkins declarative pipeline doesn’t have a proper retry mechanism for stages within the pipeline necessary to handle long-running stages on ephemeral infrastructure. You can only re-run the top-level stages, not the individual stages. So if you have 10 parallel stages and only one failed, you’ll still need to rerun all of them. Also, Jenkins built-in retry step isn’t targeted; it’ll retry a few times for any error. In contrast, we wanted to retry on specific errors.
Constraints
With these two challenges mentioned, we still had some additional constraints. So before we move forward, let’s take a look at the constraints that we had:
- We were using Kubernetes to run the CI workloads, and each stage should’ve been isolated and have its own agent (Pod).
- Our CI ran on ephemeral infrastructure (GCP Spot/Preemptible), which saves more than 80% of expenses, and that shouldn’t change.
- We already knew that we had to split the jobs into multiple Jenkinsfiles, however, we didn’t want to have too many Jenkinsfiles that could cause us to lose the end-to-end view of the CI using Jenkins Blue Ocean UI.
- We wanted to minimize the restart of the whole pipeline because of a random failure (for example, a network error or so), especially since many of the jobs were long-running and executed in parallel.
- We wanted to run the whole pipeline to the end. Even if a stage fails, we didn’t want the entire pipeline to be blocked because of it.
- We still wanted to be able to run selected parts of the pipeline. For example, we used GitHub labels to run the stages of the database or even the stages related to Postgres only.
As you can see, these constraints seem to contradict each other. Fewer Jenkinsfiles lead to more stages per file, which means if a stage fails, we needed to restart the whole top-level stage. And with ephemeral infrastructure, we were even more prone to stage failure. What a dilemma!
Solution
With a collaboration between two software engineers and one DevOps engineer, we ended up with a simple yet powerful solution to overcome long-running build limitations in Jenkins declarative pipelines.
Handling the massive number of stages
For the first challenge, we ended up with something similar to Lambda Architecture in the data world. We split the jobs among five Jenkinsfiles: two for the community edition and two for the enterprise edition, and one for tasks that are too slow or ran less frequently.
Handling the retries within stages
For the second challenge, we extended the Jenkins built-in retry step by writing our own custom steps via Shared Libraries.
We developed a custom pipeline step called conditionalRetry, which handled the errors within the stage. So if the pipeline stage returned an error, then the conditionalRetry would parse it. If it matches the defined patterns, the custom step would retry the stage; if not, the stage would fail as usual or with a warning.
As mentioned before, our infrastructure is ephemeral; thus, the nodes might vanish at any moment. That means the conditionalRetry will relaunch a new agent (pod) and redo the stage steps when the stage agent (pod) has died or been removed due to problems in the underlying infrastructure.
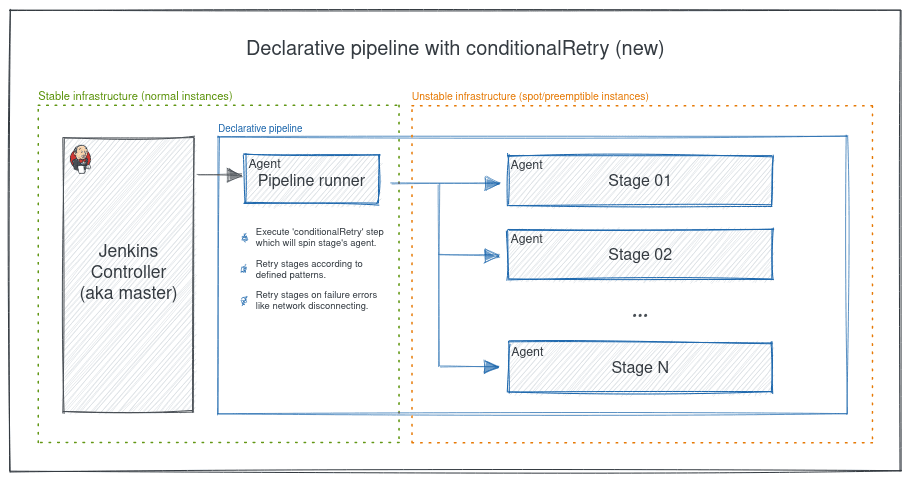
One of the biggest challenges here was what would handle the error when the stage itself is actually down. For that reason, we architected our pipelines a bit differently where each build had a tiny agent called a pipeline runner on the stable infrastructure which holds the pipeline state.
Without further ado, let’s take a look at this in action.
Architecture
First, let’s get an overview of the old and the new styles and differences between them.

The old style had the CI work as a chain of jobs; each job triggers another job until all the jobs were done. If a job failed, it would retry again multiple times. There was no end-to-end overview of the CI jobs. We had some custom tools to help us get that overview, but only at the end where the upstream-downstream architecture limited them. Moreover, it was challenging because it used JobDSL to build jobs that are difficult to learn and handle for daily use.

In the new style, the pipeline runner agent is the pipeline’s starting point, which works as an orchestrator for the stages/agents in the pipeline. The pipeline runner has responsibilities like executing the conditionalRetry step, which will spin the stage’s agent, retry stages according to defined patterns, and retry stages on failure errors like a network disconnection.
Now let’s look at the conditionalRetry flow and what actually happens within the pipeline.

- When a build is triggered, the Jenkins controller (aka master) executes the pipeline and spins the pipeline agent called a pipeline runner, which maintains the state during the whole build.
- The pipeline runner executes the conditionalRetry step, which spins the agent of each stage.
- Each stage sends its logs to the Jenkins controller.
- The conditionalRetry code on the pipeline runner scans the stage logs on the controller.
- According to the logs, the pipeline runner will take action, either rerun the stage, mark the stage as failed and stop the pipeline, or just report the failure and label the stage as “unstable” (the user configures that).
Enough with the visual art. Let’s move to another kind of art: the code!
Example
Here is an example that shows conditionalRetry in action. This pipeline runs a stage that always fails on the first run and succeeds on the second run. The conditionalRetry will take care of the error since it matches the pattern we’re looking for (a known or expected issue like network failure).
@Library('camunda-community') _
pipeline {
agent {
node {
// This is the intermediate node label. It should run on a stable infrastructure.
label 'jenkins-pipeline-runner'
}
}
stages {
stage('Set failure count') {
steps {
script {
FAILURE_COUNT = 1
}
}
}
stage('Conditional retry demo') {
steps {
conditionalRetry([
// This is the execution node label. It could run on an unstable infrastructure (spot/preemptible).
agentLabel: 'spot-instance-node',
suppressErrors: false,
retryCount: 3,
retryDelay: 5,
useBuiltinFailurePatterns: false,
customFailurePatterns: ['test-pattern': '.*DummyFailurePattern.*'],
// Demonstrate flaky stage and retry if the pattern found in the logs.
runSteps: {
sh '''
echo "The runSteps mimics the steps inside the pipeline stage."
'''
// This will fail only on the first run, and t will be skipped in the second run.
script {
if (FAILURE_COUNT == 1) {
--FAILURE_COUNT
error 'This is just an error with a DummyFailurePattern that will be matched!'
}
}
},
postSuccess: {
echo "This will be printed if the steps succeeded in the retry node/agent"
},
postFailure: {
echo "This will be printed if the steps failed in the retry node/agent"
},
postAlways: {
echo "This will always be printed after the steps in the retry node/agent"
}
])
}
}
}
}The conditionalRetry step has many parameters to customize its behavior. For example, you can suppress errors to have the rest of the stages run to the end, which is pretty helpful for long-running builds where you don’t want to fail fast. (Note: Jenkins provides an option to disable fast failing, but it only works on the top-level stage, not the whole pipeline.) Also, you can control the retry count, how much time to wait between each retry, and many other options (for more details, check the step code docs).
Here’s what that’ll look like in Jenkins Blue Ocean UI:

Notice the error happens once, then within the stage, it has been retried and succeeded.
Recap
By introducing conditionalRetry, we’ve improved Jenkins’ ability to effectively handle the errors within stages while also allowing you to strike a good balance between cost, visibility, and long-running stages.
You can actually use conditionalRetry in your pipeline too. It’s available on the Camunda Community Jenkins shared library. Also, for a complete example, you can see how the Camunda Platform 7 team uses it in action.
In the end, it’s important to mention that this post presents a solution for a unique use case. The rest of the teams at Camunda don’t use the plain Jenkins declarative pipelines or GitHub Actions.
Get Started Now
The Camunda Community Jenkins Shared Library is open, free, and is part of the Camunda Community Hub. Feel free to contribute to the Community Hub – we love feedback and value all your contributions. If you want to be part of this project or find any issue, go ahead and open an issue or create a PR.


