Back in March, I conducted the webinar: “Monitoring & Orchestrating Your Microservices Landscape using Workflow Automation”. Not only was I overwhelmed by the number of attendees, but we also got a huge list of interesting questions before and, especially, during the webinar.
I was able to answer some of these, but ran out of time to answer them all. So I want to answer all open questions in this series of seven blog posts – you can click on the hyperlinks below to navigate to the other entries.
In this blog, we’ll be exploring Camunda Best Practice questions:
- BPMN & modeling-related questions (6 answers)
- Architecture related questions (12)
- Stack & technology questions (6)
- Camunda product-related questions (5)
- Camunda Optimize-specific questions (3)
- Questions about best practices (4)
- Questions around project layout, journey and value proposition (3)
Q: Business data versus workflow data: if you cannot tear them apart, how can you keep them consistent? Are the eventual/transactional consistency problems simpler or more complex with Camunda BPM in the equation?
This is quite a complex question, as it depends on the exact architecture and technology you want to use.
Example 1: You use Camunda embedded as a library, probably using the Spring Boot starter. In this case, your business data could live in the same database as the workflow context. In this case you can join one ACID transaction and everything will be strongly consistent.
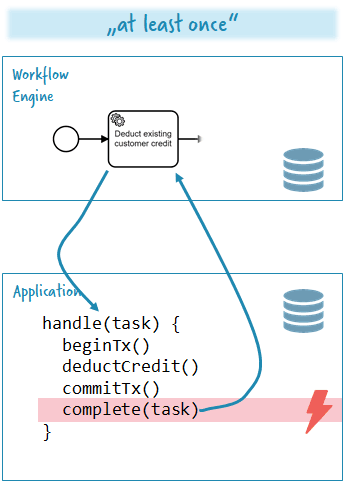
Example 2: You leverage Camunda Cloud and code your service in Node.JS, storing data in some database. Now you have no shared transaction. Now you start living in the eventual consistent world and need to rely on “at-least-once” semantics. This is not a problem per se, but at least requires some thinking about the situations that can arise. I should probably write a dedicated piece about that, but I had used this picture in the past to explain the problem:

In this example, you can end up with money charged on the credit card but the workflow not knowing about it. But in this case you leverage the retry capabilities and will be fine soon (=eventually).
Q: Is it a good idea to save the process data into a single complex object with JSON notation?
As always: It depends.
But if the data cannot live anywhere else, serializing the data into the workflow is at least an option. And if you serialize it, JSON might also be a good idea. Please note, that you cannot query for data in that process variable anymore (or do a text query at max).
So it depends. The best practice Handling Data in Processes might help to judge that.
Q: How to handle the filtering of information allowed or not to be seen by a user of the process?
I guess this refers to task lists. There are two layers to look at it. Is it important that the user is not able to get the data at all — not even by looking at the data transferred to his browser via JSON in the background?
If yes, you need to work with data mappings to make sure only the variables are available in the task that should be readable and configure permissions accordingly.
If no, the easiest option is to simply not show certain data in the forms for users.
Q: How to do microservice versioning and workflow versioning and manage both in harmony and congruent?
I love this question, but it depends. Versioning Process Definitions might give you a good starting point for the workflow angle of it.
For the microservices angle of it there are tons of other material available discussing tolerant readers and overall versioning approaches. This is a rabbit hole I don’t want to follow here.
Ready for more?
Next week we’ll be taking a closer look at questions on project layout, journey and value proposition. But if you can’t wait until the next blog, you can check out the original here on my Medium site.
Getting Started
Getting started on Camunda is easy thanks to our robust documentation and tutorials





