We regularly answer questions around how technical transactions work when using Camunda (in the latest version 8.x) and the Spring framework. For example, what happens if you have two service tasks, and the second call fails with an exception? In this blog post, I’ll sketch typical scenarios to make the behavior more tangible. I will use code examples using Java 17, Camunda 8.3, Spring Zeebe 8.3, Spring Boot 2.7 and Spring Framework 5.3.
Let’s use the simple BPMN process below:

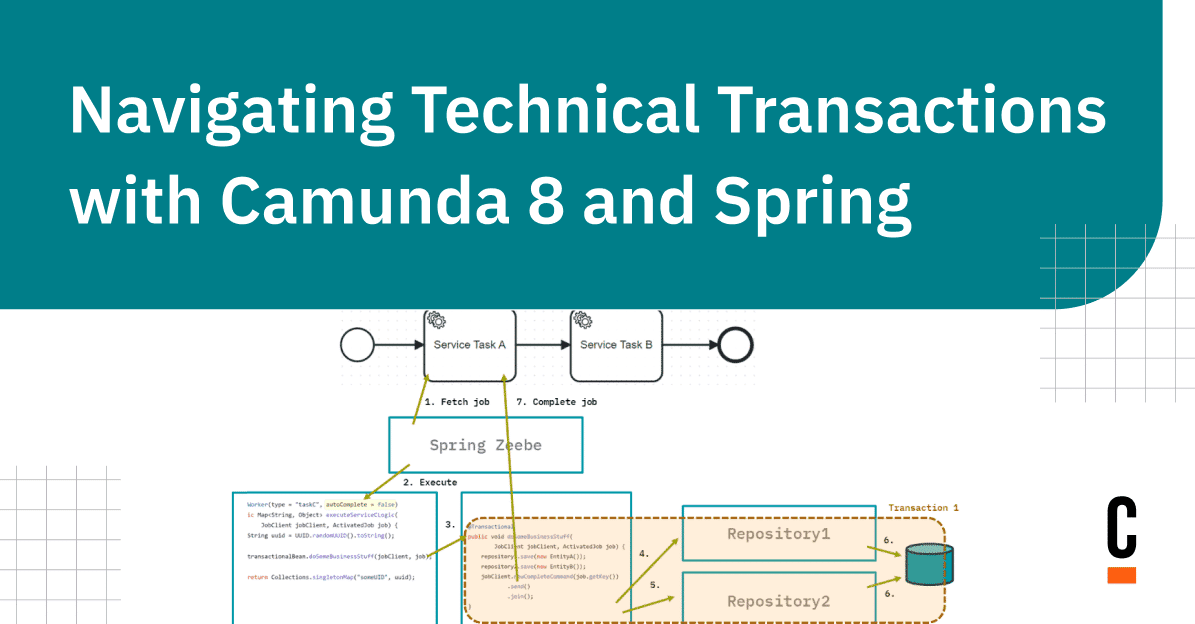
Every service task has an associated job worker, and every job worker will write two different JPA entities to a single database using two different Spring Data Repositories:

We can use our example to show technical implications of how you write these workers. The three workers (for task A, B, and C) are implemented slightly differently.
Let’s go over the different scenarios one by one.
Scenario A: Job worker calls repositories directly
The job worker is a Spring bean and gets the repositories injected. The job worker uses these repositories to save the new entities:
@Autowired
private SpringRepository1 repository1;
@Autowired
private SpringRepository2 repository2;
@JobWorker(type = "taskA")
public void executeServiceALogic() {
repository1.save(new EntityA());
repository2.save(new EntityB());
}Note that we haven’t configured anything about transaction management yet. Hence, the call to the repositories will not run within an open transaction, so each repository will create its own transaction, which will be committed right after saving the entity. This means that the second repository will create its own transaction. In this case, the two repository calls don’t span a joined transaction. This is also visualized here:

Completing the job within Zeebe comes after both transactions are committed. Zeebe does not need a transaction manager and cannot join one.
If you are more into sequence diagrams, you can see the same information presented here:

What does this mean for you? To understand implications of transactional behavior, you need to look at failure cases. In the example above, we could have the following interesting error scenarios:
- The worker crashes after the job is activated.
- The worker crashes after the first repository successfully has saved its entity.
- The worker crashes after the second repository successfully has saved its entity.
- Something crashes after the job completion was sent to Zeebe.
The error cases are indicated in the sequence diagram below:

Let’s go over these scenarios one by one.
#1 The worker crashes after the job was activated
Nothing really happened so far. The job is locked for the specific job worker for some time, but after this timeout the job will be picked up by any other job worker instance. This is normal job retrying and no problem at all.
#2 The worker crashes after the first repository successfully saved its entity
The transaction of Repository1 is already committed, so EntityA is already persisted in the database. This will not be rolled back.
As the job worker crashed, EntityB will never be written and the job will not be completed in Zeebe. Now, the retrying logic of Zeebe will make sure that another job worker will execute this job again (after the lock timeout expires).
This has two important implications:
- Because of the retry, the
repository1.savemethod will be called again. That means we have to make sure this isn’t a problem, which is known as idempotency. We’ll revisit this later. - We might have an inconsistent business state for a (short) period of time, as a business might expect that EntityA and EntityB always must exist together. Assume a more business-relevant example, where you might deduct credit points in a first transaction to extend a subscription in a second transaction. The inconsistency now is a customer with reduced credits, but the same old subscription. This is also known as eventual consistency, and a typical challenge in microservice environments. I talked about it in Lost in Transaction. The gist is that you have two possibilities here: (1) decide that this is unbearable and adjust your transaction boundaries, which I will discuss later, or (2) live with this inconsistency as the retrying ensures it is resolved eventually.
In our example, consistency is restored after the retry succeeded and all methods were correctly called, so this might not be a problem at all. See also embracing business transactions and eventual consistency in the Camunda best practices.
Sometimes people complain about why Camunda can’t simply “do transactions” to avoid thinking about those scenarios. I already wrote about achieving consistency without transaction managers and I still believe that distributed systems are the reality for most of what we do nowadays. Additionally, distributed systems are by no means transactional. We should embrace this and get familiar with the resulting patterns. It is actually also not too hard—the above two implications are already the most important ones, and they can be handled.
Idempotency
Let’s get back to idempotency. I see two easy ways to sort this out (see also 3 common pitfalls in microservice integration — and how to avoid them):
- Natural idempotency. Some methods can be executed as often as you want because they just flip some state. Example:
confirmCustomer() - Business idempotency. Sometimes you have business identifiers that allow you to detect duplicate calls. Example:
createCustomer(email)
If these approaches will not work, you will need to add your own idempotency handling:
- Unique Id. You can generate a unique identifier and add it to the call. Example:
charge(transactionId, amount). This has to be created early in the call chain. - Request hash. If you use messaging you can do the same thing by storing hashes of your messages.
In our scenario above, we might be able to store a UUID in the process and in the entities, and that allows us to do a duplicate check before we insert entities:
@JobWorker(type = "taskA-alternative-idempotent")
Public void executeServiceALogic(@Variable String someRequestUuid) {
repository1.save(new EntityA().setSomeUuid(someRequestUuid));
repository2.save(new EntityB().setSomeUuid(someRequestUuid));
}But without knowing the exact context, it is impossible to advise on the best strategy. Because of this, it is especially important to have those problems top of mind to make sure to plan for the right identifiers to be created at the right time and added to relevant APIs.
See also writing idempotent workers in the Camunda best practices.
#3 The worker crashes after the second repository successfully saved its entity
This is very comparable to #2, but this time both entities were written to the database before the crash. So with the retry, both calls will be re-executed. Therefore, the call to repository2 needs to be idempotent.
#4 The worker or network crashes after the job completion was sent to Zeebe
After sending the job complete command to Zeebe, which is done automatically by Spring Zeebe for you, either the server, the network, or even the client might crash. In all of those situations we don’t know if the job completion was accepted by the Zeebe engine.
Just for the sake of completeness, Zeebe has a transactional concept internally. There is a very defined state for every incoming command, and only if it is committed, which also includes replication to all brokers, will it be executed.
So if it is not yet committed, we are back in situation #3 and will retry the job. If it is committed, the workflow will move on. In case of a network failure the client application will not know that everything worked fine but catch an exception instead.
This is not really a problem and the business state is consistent, but you should not depend on the successful job completion to achieve more business logic in your client application, as this code then might not be executed in case of an exception. Let’s revisit this when talking about Service Task C.
Scenario B: JobWorker calls @Transactional bean
Instead of calling the repositories directly from the job worker, you might have a separate bean containing the business logic to do those calls, and then call this bean from your job worker:
@Autowired
private TransactionalBean transactionalBean;
@JobWorker(type = "taskB")
Public void executeServiceBLogic() {
transactionalBean.doSomeBusinessStuff();
}This might be a better design anyway, as the job worker is just an adapter to call business logic, not a place to implement business logic.
But despite this, now you can use the @Transactional annotation to change the transactional behavior. This will ensure all repository calls within that bean will use the same transaction manager, and this transaction manager will either commit or rollback completely.

This influences the third error case from above: if the worker application crashes after writing the first entity, the transaction is not committed and no entity is in the database.
While this is probably a great improvement for your application, and it also might fit your consistency requirements more, note that it does not solve the other error scenarios, and you still have to think about idempotency.
Note, that technically you could also annotate the job worker method with @Transactional, (leading to the same behavior as just described) but we typically advise not to do this as it can easily lead to confusion instead of clarity about the transaction boundaries.
Scenario C: Job completion is called within the transaction boundary
Now let’s look into the third possible scenario: you could disable the Spring Zeebe auto-completion of the job, but do the API call to complete the job yourself. Now you can influence the exact point in time this call is done, which makes it possible to call it from within your transactional bean.

For the error scenario 2 and 3 from above (job worker crashes after entity A or B was inserted) nothing has changed: the error will lead to a normal rollback, nothing has happened at all and retries will take care of things.
But consider error scenario 4 where the behavior changes big time. Assume the job completion command was committed properly on the workflow engine, but the network failed to deliver the result back to your client application. In this case, the blocking call completeCommand.send().join() will result in an exception. This in turn will lead to the Spring transaction being aborted and rolled back. This means that the entities will not be written to the database.
I want to emphasize this: The business logic was not executed, but the process instance moved on. There will be no more retries.
At-least-once vs. at-most-once
So we just changed the behavior to what is known as at-most-once semantic: We can make sure the business logic is called at most once, but not more often. The catch is, it might never be called (otherwise it would be called exactly once).
This is a contrast to our scenario A and B where we had a at-least-once semantic: We make sure the business logic is called at least once, but we might actually call it more often (due to the retries). The following illustration taken from our developer training emphasizes this important difference:

You might want to revisit achieving consistency without transaction managers to read more about at-least-once vs at-most-once semantics, and why exactly once is not a practical way to achieve consistency in typical distributed systems.
Note, that there is one other interesting implication of at-most-once scenarios, that is probably not obvious: The workflow engine can move on, before the business logic is committed. So in the above example, the job worker for service task B might be actually started, before the changes of service task A are committed, for example visible in the database. If B expects to see the data there, this might lead to problems you have to be aware of.
To summarize, this change might not make sense in our example. Use cases for at-most-once semantics are really rare; one example could be customer notifications that you prefer to lose over sending it multiple times and confuse a customer. The default is at-least-once, which is why Spring Zeebe’s auto completion also makes sense.
Thinking about transaction boundaries
I wanted to give you one last piece of food for thought in this already too long post. This is about a question we also get regularly: can’t we do one big transaction spanning multiple service tasks in BPMN? So basically this:

The visual already gives you a clue; this is neither technically possible with Camunda 8, nor is it desirable. As mentioned, Camunda will not take in any transaction, so that’s why it is not possible. But, let me quickly explain why you also do not want it.
1. It couples the process model to the technical environment
Assume you have the model above in production and rely on the functionality that in case of any error, the process instance is simply rolled back. Now, a year later, you want to change the process model. The business decides that before doing Task B you first need to manually inspect suspicious process instances. The BPMN change is simple:

But notice that now you will no longer rollback Service Task A when B fails for cases that go through the user task.
You would also not see the exact transaction boundaries visually in your process model, so you will need to explain this specialty every time you discuss a model. But good models should not need too many additional words!
2. It is only possible in edge cases
Such a transactional integration would only work when you use components that either work in one single database only, or that support two-phase commit, also known as XA transactions. At this point I want to quote Pat Helland from Amazon: “Grown-ups don’t use distributed transactions.” Distributed transactions don’t scale, and a lot of modern systems don’t provide support for it anyway (think for example of REST, Apache Kafka, or AWS SQS). To sum this up: in real-life, I don’t see XA transactions used in distributed systems successfully.
If you are interested in such discussions, the domain-driven design or microservices community has a lot of material on it. In lost in transaction I also look at how to define consistency (= transaction) boundaries, which are typically tied to one domain. Translated to the problem at hand I would argue that if something has to happen transactionally, it should probably happen in one service call, which boils down to one transactional Spring bean. I know this might simplify things a bit—but the general direction of thought is helpful.
Summary
So this was a lot, let me recap:
1. Camunda 8 does not take part in Spring driven-transactions. This typically leads to at-least-once semantics due to retrying of the engine.
2. You can have transactional behavior within the scope of one service task. Therefore, delegate to a @Transactional method in your own Spring bean.
3. You should have a basic understanding of idempotency and eventual consistency, which you need for any kind of remote calls anyway, which means: with the first REST call in your system!
4. Failure scenarios are still clearly defined and can be taken care of, not using XA transactions and two-phase doesn’t mean we are going back to chaos!
As always: I love to hear your feedback and am happy to discuss.


