

When using Camunda 8, you might encounter the concept of an exporter. An exporter is used to push out historic data, generated by our processing engine, to a secondary storage.
Our web applications have historically used importers and archivers to consume, aggregate, and archive historical data provided by our Elasticsearch (ES) or OpenSearch (OS) Exporter.
In the past year, we’ve engineered a new Camunda Exporter, which brings the importer and archiving logic of web components (Tasklist and Operate) closer to our distributed platform (Zeebe). This allows us to simplify our installation, enable scalability for web apps, reduce the latency to show runtime and historical data, and reduce data duplication (resource consumption).
In this blog post, we want to share more details about this project and the related architecture changes.
Challenges with the current architecture
Before we introduce the Camunda Exporter, we want to go into more detail about the challenges with the current Camunda 8 architecture.

When a user sends a command to the Zeebe cluster (1), it is acknowledged (2) and processed by the Zeebe engine. The engine will confirm the processing with an event.
The engine has its own primary data store for runtime data. The primary data store is optimized for low-latency local access. It contains the execution state that allows the engine to execute process instances and move its data along in their corresponding processes.
Our users need a way to search and visualize process data (running and historical data), so Camunda 8 makes use of Elasticsearch or OpenSearch (RDBMS in the future) as secondary storage. It allows the separation of concerns between runtime data for process execution and history data for querying.
Camunda’s exporters are a bridge between primary and secondary data stores. The exporters allow the Zeebe system to stream out data (events) (3). Within the Camunda 8 architecture, we support both the ES and OS exporters. For more information about this concept and supported exporters, please visit our documentation.
The exported data is stored in what we unofficially refer to as Zeebe indices inside ES or OS. Web applications like Tasklist and Operate make use of importers and archivers to read data from Zeebe indices (4), aggregate, and write them back into their indices (5). Based on these indices, users can query and search process data (6).
Performance
Customers have reported performance issues, which are inherited with this architecture. For example, the delay of data shown in Operate can range from around five seconds to, in the worst scenarios, minutes or hours.
The time is spent in processing, exporting, flushing, importing, and flushing again, before the users see any data change. For more detailed information, you can also take a look at this blog post.
This means the user is never able to follow a process instance in real time. But there is a general expectation that it is at least close to real time, meaning that it should at max take 1-2 seconds to show updates.
Reducing such latency and improving the general throughput needs a general architecture change.
Scalability
What we can see in our architecture above is that when we scale Zeebe clusters and partitions or set them up for large workloads, the web applications do not scale automatically with it, as they are not directly coupled.
This means additional effort to make sure the web applications can handle certain loads. The current architecture limits the general scalability of the web applications, due to the decoupling of exporter-importer and no real partitioning of data in the secondary storage.
We want to make the web application more scalable to handle changing processing workloads.
Installation complexity
You can run the different components of the Camunda platform separately, e.g. separate deployments for Zeebe, Tasklist, Operate, etc. This gives you a lot of flexibility and allows for massive scale. But at the same time, this makes the installation harder to do—even with the help of Helm charts.
We want to support a simpler installation as an alternative. That wasn’t possible in this architecture because of a missing single application and the need for separate components.
Data duplication and resource consumption
Web applications like Operate and Tasklist have historically been grown and developed separately. As we have seen, they could have been deployed separately as well.
This was also why they had separate schemas. Tasklist used a subset of Operate schema but added additional necessary indices to store information about user tasks, etc. When deploying both applications, this caused an unnecessary duplication of data in ES or OS.
As a consequence of this, we are consuming more disk space than necessary. Furthermore, ES/OS has a higher load on indexing new data than should be necessary.
We want to reduce this to minimize the memory and disk footprint needed to run Camunda.
One exporter to rule them all
Understanding those challenges, we rearchitected our platform to get rid of the aforementioned challenges. In the new architecture, we have built a Camunda exporter to replace the exporter/importer from the old architecture.
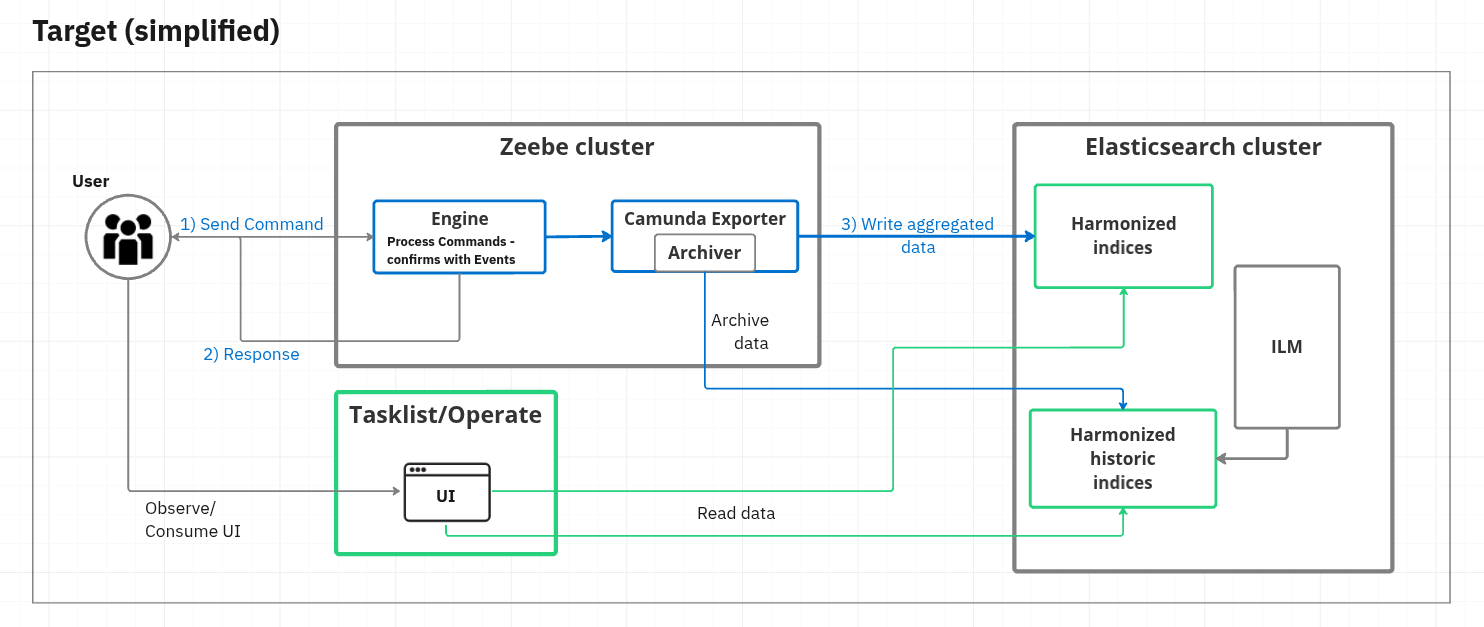
The Camunda Exporter brings the importer and archiving logic of web components (Tasklist and Operate) closer to the distributed platform (Zeebe).
The exporter consumes Zeebe records, aggregates data, and stores the related data into shared and harmonized indices that are used by both web applications. Archiving of data is done in the background, coupled with the exporter but not blocking the exporter’s progress.
Introducing this Camunda Exporter allows it to scale with Zeebe partitions and simplifies the installation, as importer and archiver deployments will be removed in the future.
The architecture diagram above is a simplified version of the actual work we have done. It shows an installation for a greenfield and a new cluster (no previous data).
More complex is a brownfield installation as shown in the diagram below, where data already exists.
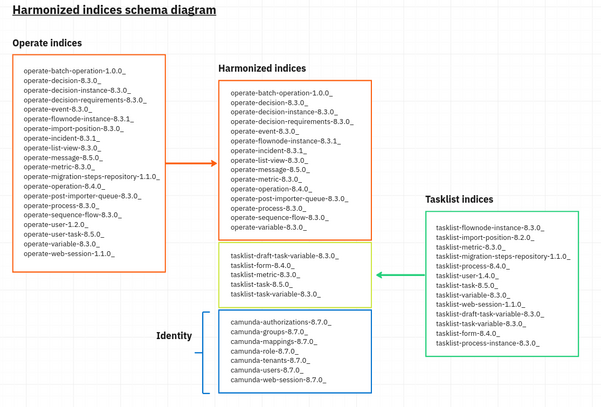
We were able to harmonize the existing index schema used by Tasklist and Operate, reducing data duplication and resource consumption. Several indices can now be used by both applications without a need to duplicate the data.
With this new index structure, there is no need for additional Zeebe indices anymore.
Note: With 8.8, we likely will still have the importer/exporter (including Zeebe indices) to make use of Optimize (if enabled), but we aim to change that in the future as well.
Migration (brownfield installation)
Brownfield scenarios, where the data already exists and processes are running in an old architecture, are much more complex than greenfield installations. We have covered this in our solution design and want to briefly talk about it in this blog post. A more detailed update guide will follow with the Camunda 8.8 release.
When you update to the new Camunda version, there will be no additional effort for the user regarding data migration. We are providing an additional migration application that takes care of enhancing process data (in Operate indices) which can be used by Tasklist. Other than that, all existing Operate indices Operate can be used by Tasklist.
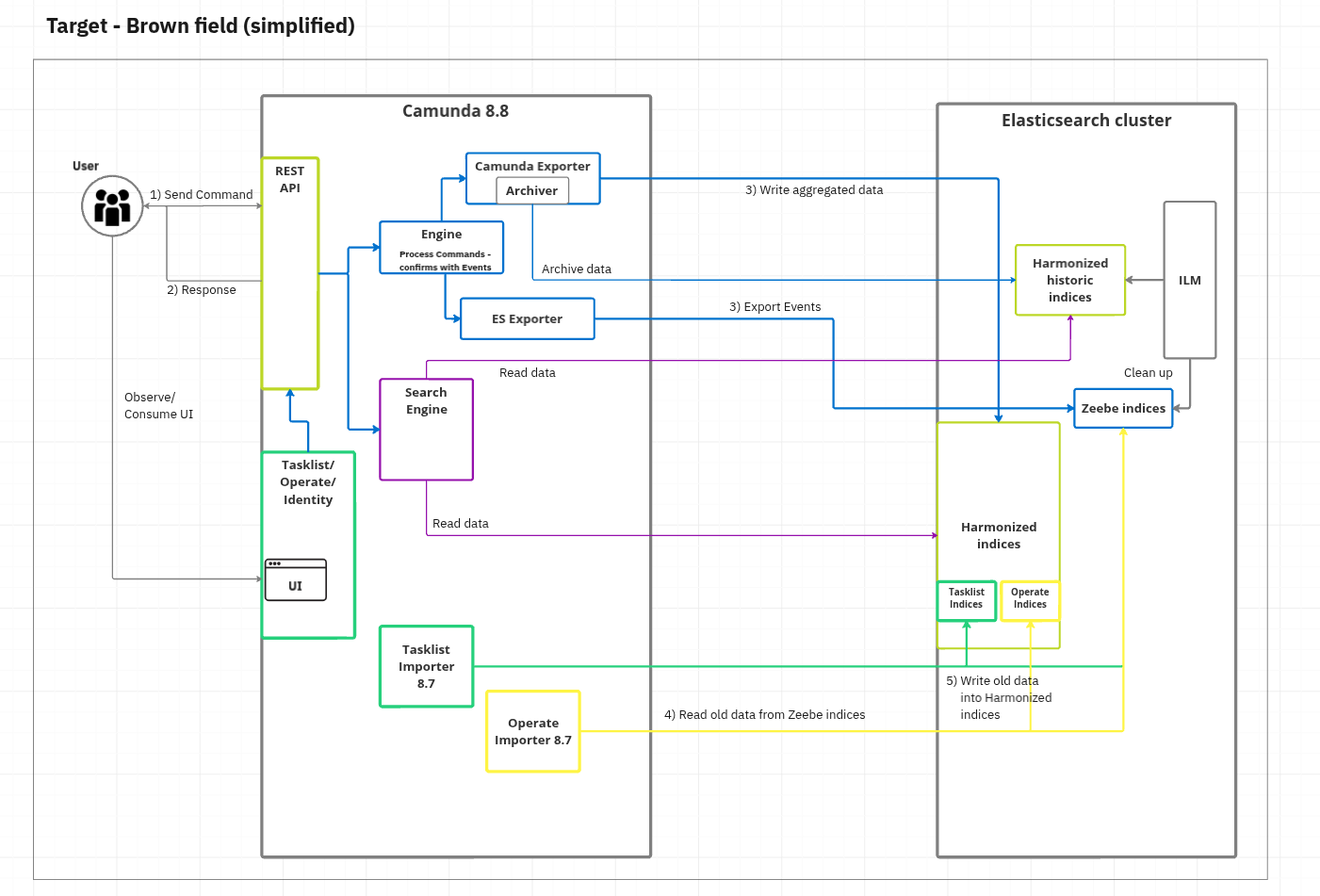
Reducing the installation complexity is a slower process for brownfield installations. Importers still need to be executed to drain the preexisting data in indices created by ES or OS exporters.
After all older data (produced before the update) is consumed and aggregated, importers and exporters can be turned off as well but can also be kept for simplicity. The importers will communicate via metrics if they are done and by writing to a special ES/OS index. More details will be provided in the following update guide.
Conclusion
The new Camunda Exporter helps us achieve a more streamlined architecture, better performance, and stability (especially concerning ES/OS). The target release for the Camunda Exporter project is the 8.8 release.
To recap the highlights of the new Camunda Exporter, we can:
- Scale with Zeebe partitions, as exporters are part of partitions. The data injection and the data archiving scales inherently.
- Reduce resource consumption with harmonized schema. Data is not unnecessarily duplicated between web applications. ES and OS are not unnecessarily overloaded with index requests for duplicated data.
- Improve performance, due to reducing additional hop. As we do not need to wait for ES/OS to flush twice and make data available, we can reduce one flush interval from our equation. We don’t need to import the data and store it in Zeebe indices, so we shorten the data pipeline. This was shown in one of our recent chaos days but needs to be further investigated and benchmarked, especially with higher load scenarios.
- Simplify installation by bringing business logic closer to the Zeebe system. We no longer need separate applications or components for importing and archiving data. It can be easily enabled within the Zeebe brokers. The Camunda Exporter has everything built in.
I hope this was insightful and helpful to understand what we are working on and what we want to achieve with the newest Camunda Exporter. Stay tuned for more information about benchmarks and other updates.
Join us at CamundaCon to learn more
Looking to learn more about this new architecture and how the Camunda Exporter will help you? I’ll be giving a talk on the new Camunda Exporter at CamundaCon Amsterdam in May. Join us there in person to catch the session and so much more.
Start the discussion at forum.camunda.io