

Currently, most organizations are asking themselves how they can effectively integrate artificial intelligence (AI) agents. These are bots that can take in some natural language query and perform an action.
I’m sure you’ve already come across various experiments that aim to crowbar these little chaps into a product. Results can be mixed. They can range from baffling additions that hinder more than help to ingenious, often subtle enhancements that you can’t believe you ever lived without.
It’s exciting to see the innovation that’s going on, and because of the kind chap I am, I’ve been wondering about how we can build our way towards improving actual end-to-end business processes with AI agents. Naturally, this requires us to get to a point where we trust agents to make consequential decisions for us, and even trust them to action those decisions.
So, how do you build an infrastructure that uses what we’ve learned about the capabilities of AI agents without giving them too much or too little responsibility? And would end users ever be able to trust an AI to make consequential decisions?
How AI agents will evolve
Most people I know have already integrated some AI into their work in some great ways. I build proof of concepts with Camunda reasonably often and use Gemini or ChatGPT to generate test data or JSON objects—it’s very handy. This could be expanded into an AI agent by suggesting that it generate the data and also start an instance of the process with the given data.
This also tends to be the way organizations are using AI agents—a black box that takes in user input and responds back with some (hopefully) useful response after taking a minor action.
Those actions are always minor of course and it’s for good reason—it’s easy to deploy an AI agent if the worst it’s going to do is feed junk data into a PoC. The AI itself isn’t required to take any action or make any decisions that might have real consequences; if a human makes the decision to use a court filing generated by ChatGPT… Well, that’s just user error.
For now, it’s safer to keep a distance from consequential decision-making and the erratic and sometimes flawed output of AI agents. This more or less rules out utilizing the full potential of AI agents—because at best you want them in production systems making decisions and taking consequential actions that a human might do.
It’s unrealistic, however, to assume that this will last for long. The logical conclusion of what we’ve seen so far is that AI agents will be given more responsibility regarding the actions they can take. What’s holding that step back is that no one trusts them because they simply don’t produce predictable, repeatable results. In most cases, you’d need them to be able to do that in order to make impactful decisions.
So what do we need to do to make this next step? Three things:
- Decentralize
- Orchestrate
- Control
Agentic AI orchestration
As I mentioned, I use several AI tools daily. Not because I want to, but because no single AI tool can accurately answer the diversity of my queries. For example, I mentioned how I use Gemini to create JSON objects. I was building a small coffee order process and needed an object containing many orders.
{"orders" : [
{
"order_id": "20240726-001",
"customer_name": "Alice Johnson",
"order_date": "2024-07-26",
"items": [
{
"name": "Latte",
"size": "Grande",
"quantity": 1,
"price": 4.50
},
{
"name": "Croissant",
"quantity": 2,
"price": 3.00
}
],
"payment_method": "Card"
},
{
"order_id": "20240726-002",
"customer_name": "Bob Williams",
"order_date": "2024-07-26",
"items": [
{
"name": "Espresso",
"quantity": 1,
"price": 3.00
},
{
"name": "Muffin",
"quantity": 1,
"price": 2.50
},
{
"name": "Iced Tea",
"size": "Medium",
"quantity": 1,
"price": 3.50
}
],
"payment_method": "Cash"
}
]}I then needed to use Friendly Enough Expression Language (FEEL) to parse this object to get some kind of specific information.
I didn’t use Gemini for this because it reliably gives me bad information when I need a FEEL expression. This is for a few reasons. FEEL is a new and relatively niche expression language so there’s less data for it to be trained on. Also, I’m specifically using Camunda’s FEEL implementation, which contains some additional functions and little quirks that need to be considered. If I asked Gemini to both create the data object and then go ahead and use FEEL to get the first order in the array, I get this:
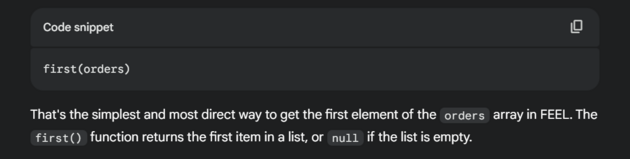
This response is a pack of lies. So instead I ask an AI agent which I know has been trained specifically and exclusively on Camunda’s technical documentation. The response is quite different and also quite correct.

I’m usually confident that Camunda’s own AI copilot and assistants will give me the correct information. It not only generates the expression, it also runs the expression with the given data to make sure it works. Though the consequences aren’t so drastic. I know FEEL pretty well, so I’m going to be able to spot any likely issues before putting it into production.
In this scenario, I’m essentially working as an orchestrator of AI agents. I’m making decisions to use a specific agent based on two main factors.
- Trust: Which Agent do I trust to give me the correct answer?
- Consequences: How impactful are the consequences of trusting the result?
This is what’s blocking the effectiveness of true end-to-end agentic processes. I don’t know if I can trust a given agent enough to decide something and then take action that might have real consequences. This is why people are okay with asking AI to summarize a text but not to purchase flowers for a wedding.
Truth and consequences
So enough theory, let’s talk about the practical steps to increase trust and control consequences in order to utilize AI Agents fully. As I like doing things sequentially, let’s take them one at a time.
Trust
We’ve all experienced looking at the result from an AI model and asked ourselves, “Why?” The biggest reason to distrust AI agents is that, in most cases, you’ll never be able to get a good answer to why a result was given. In situations where you require some kind of audit of decision-making or strict guardrails in place, you really can’t rely on a black box like an AI agent.
There is a nice solution to this though—chain of thought. This is where the AI is clear about how the problem was broken down and subsequently lays out its thought process step by step. The clear hole in this solution is that someone is needed to look over the chain of thought, and here is where we can start seeing how orchestration can lend a hand.
Orchestration can link together services in a way that sends a query to multiple agents. When both have returned with their answer and chain of thought, a third agent can act as a judge to determine how accurate the result is.
Continuing with my example, it would be easier to tell a generic endpoint, “I’m using Camunda and need to use a FEEL expression for finding the first element in an array,” and have faith that this question will be routed to the agent best suited to answer it. In this case, that would be Camunda’s kapa.ai instance.
Building this with an orchestrator like Camunda that uses BPMN would be pretty easy.
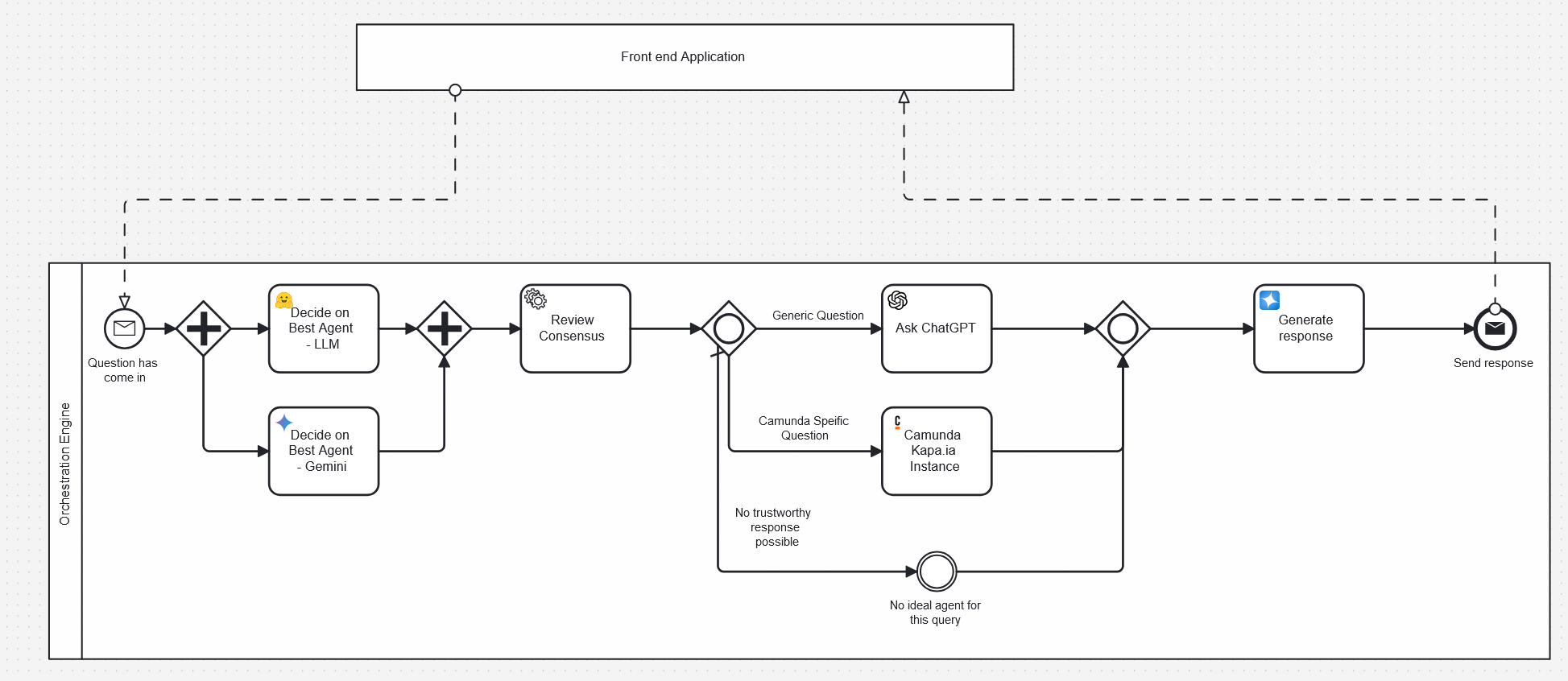
In this process the query is sent into a process instance. Two different AI agents are triggered in parallel and asked who is best at handling this kind of request. The result is passed to a third agent that can review the chain of thought and make a determination from the results of both. In this case it’s probably clear that FEEL is something a Camunda AI would do a pretty good job of answering and you’d expect the process to be sent off in that direction.
In this case we’ve created a maintainable system where more trustworthy responses are passed back to the user along with a good indication of why a certain agent was chosen to be involved and why a certain response was given.
Consequences
Once trust is established, it’s not hard to imagine that you’d start to consider actions that should be taken. Let’s imagine that a Camunda customer has created a support ticket because they’re also having trouble getting the first element in an array. A Camunda support person could see that and think, That’s something I’m confident kapa.ai could answer—and in fact, I should just let the AI agent respond to this one.
In that case, we just need to make some adjustments to the model.
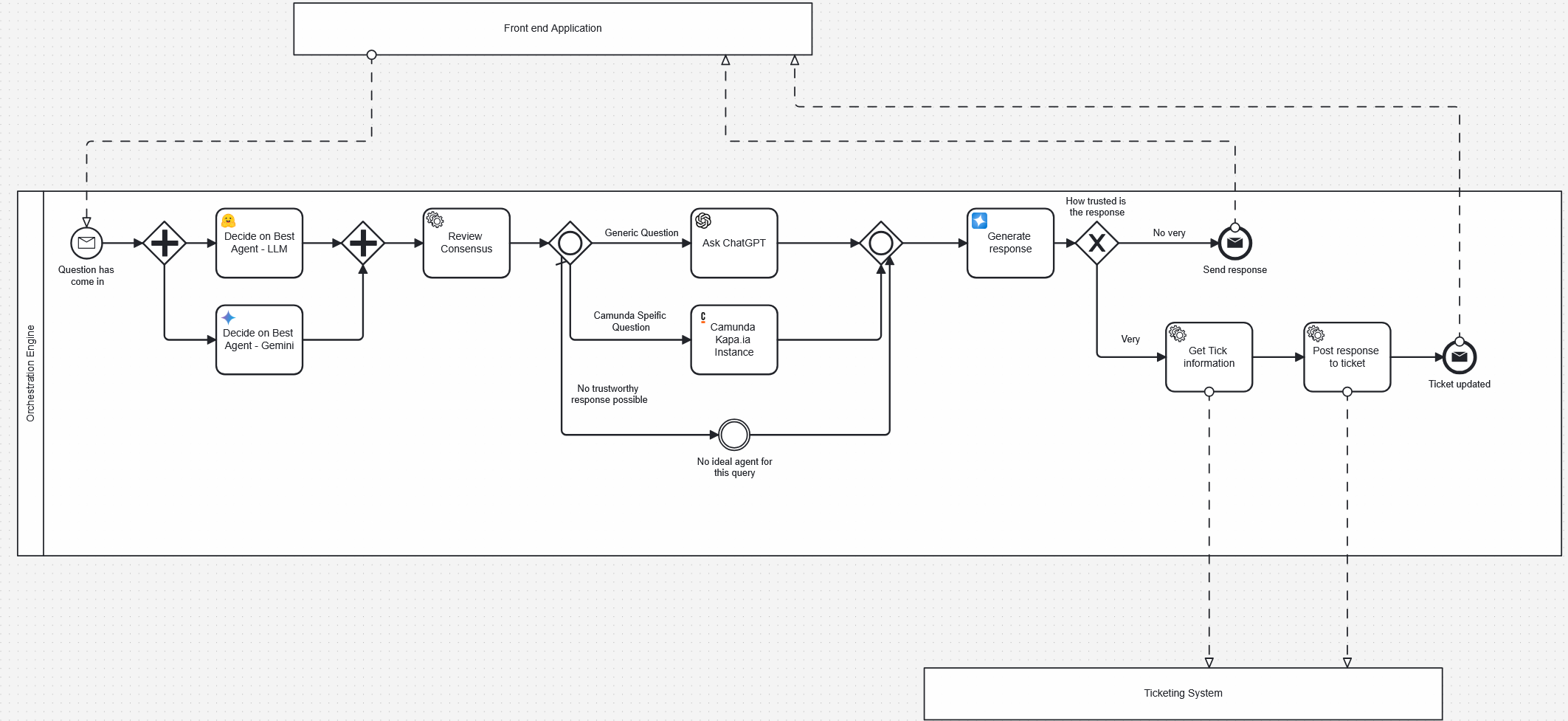
In this model, we’ve introduced the action of accessing the ticketing system to find the relevant ticket and then updating the ticket with a trustworthy answer. Because of how we’ve designed the process, we would only do this in cases where we have a very high degree of trust. If we don’t, the information will be sent back to the support person, who can decide what to do next.
The future of AI orchestration
Providing independent, narrowly trained agents and then adding robust, auditable decision-making and orchestration around how and why they’re called upon will initially help users trust results and suggestions more. Beyond that, it will give architects and software designers the confidence to build in situations where direct action can be taken based on these trustworthy agents.
An orchestrator like Camunda is essential for achieving that step because it already specializes in integrating systems and lets designers tightly control how and why those systems are accessed. Another great advantage is far better auditability. Combining the data generated from stepping through the various paths of the process with the chain of thought output from each agent gives a complete picture of how and why certain actions were taken.
With these principles, it would be much easier to convince users that actions performed by AI without user supervision would be trustworthy and save a huge amount of time and money for people by removing remedial work like checking and verifying before taking additional steps.
Of course, it’s not true for everything, and I’m happy to say that I feel we should still leave court filing to humans. Eventually though I would expect we could offer AI agents not just the ability to action their suggestions, but to also choose the specific action.
BPMN has a construct called an ad-hoc subprocess in which a small part of the process decision-making can be handed over to a human or agent. This could be used to give an AI a limited amount of freedom about what action is best.
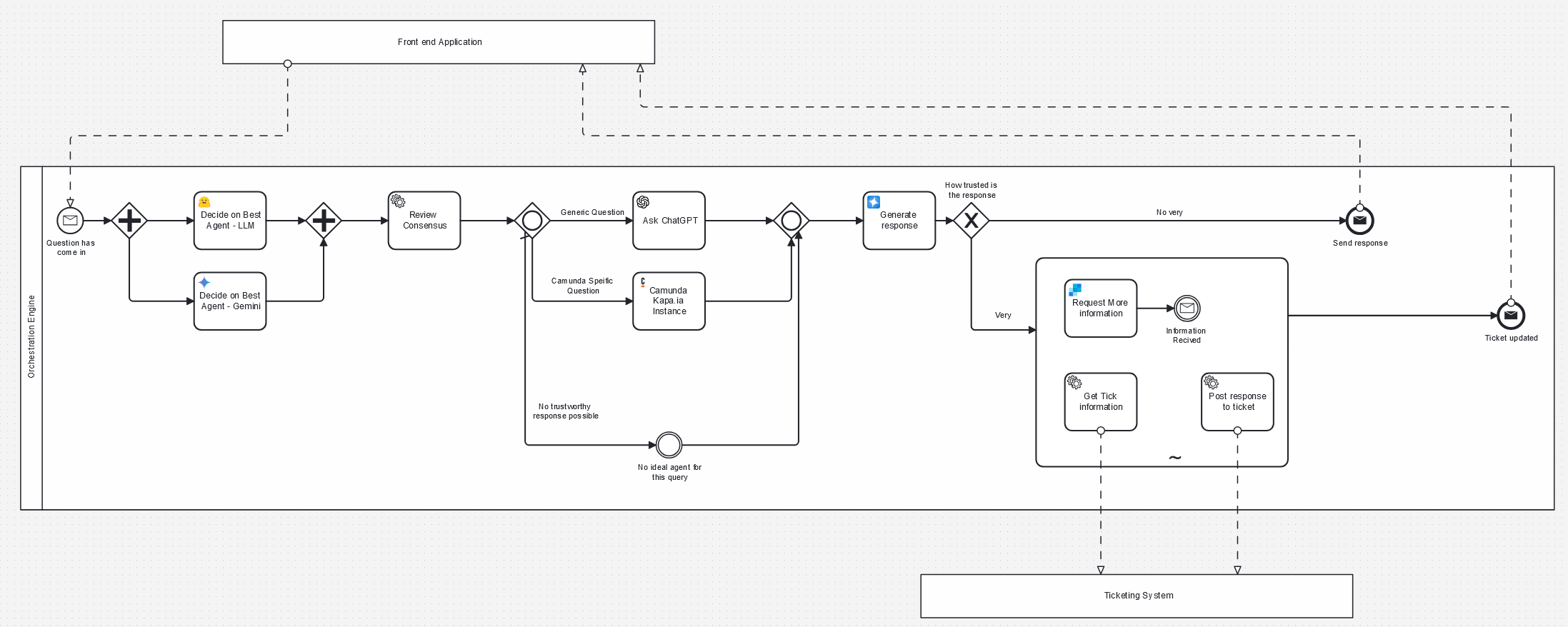
In the case above I’ve added a way for an AI agent to choose to ask for more information about the request if it needs to—it might do this multiple times before eventually deciding to post a response to the ticket, but the key thing is that if the agent knows it would benefit from more information it can perform an action that will help it make the final decision.
The future is trusting agents with what we believe they can achieve. If we give them access to actions that can help them make better choices and complete tasks, they can be fully integrated into end-to-end business processes.
Learn more about AI and Camunda
We’re excited to debut AI-enabled ad-hoc subprocesses and much more in our coming releases, so stay tuned. You can learn more about how you can already take advantage of AI-enabled process orchestration with Camunda here.
Start the discussion at forum.camunda.io