

Capital One is a bank, but it’s a bank built like a technology company. Technology is central to everything they do. They have more than 12,000 people in their tech organization, most of them software engineers. They implement the latest and greatest in technology, both products as well as methodologies, that allow their engineers to build the best experiences for their customers.
In addition, as a company, Capital One is all in on the cloud, and have been so since they left their data centers in 2020. They have been building modern applications using cloud-native services for many years. They use real-time streaming data at scale, machine learning, and the power of the cloud to deliver intelligent and personalized experiences to millions of our customers. And they are an open-source-first company, and sponsor many foundations to help keep open source sustainable. In 2014, they made a bold declaration that Capital One will be an open source first company. And they have contributed more than 40 software projects to the open source community.
Raghavan Sadagopan, an engineer and architect at Capital One, and Lakshmi Narayan, a solutions architect at Capital One, joined us at CamundaCon 2023 in New York, and talked about the solution their team built with AWS and Camunda to offer the best technology experience to enable engineers to spend more time solving hard technology challenges, as well as helping process modelers do their job more efficiently.
As a large enterprise, Capital One has a lot of business processes that require humans to make some decisions. There are a lot of applications and products that people use across the company to help people make those decisions. Raghavan and Lakshmi’s team discovered that their product and business stakeholders were using these productivity tools because there wasn’t a better technology implementation for their decisioning process. They felt this was evidence of a need to think broad, to take a step back, and seriously consider how to provide a way for their stakeholders to have a better technology experience that would allow them to do their jobs more efficiently than run and maintain an engine.
That led them to think about process orchestration. Within process orchestration, there are two broad elements.
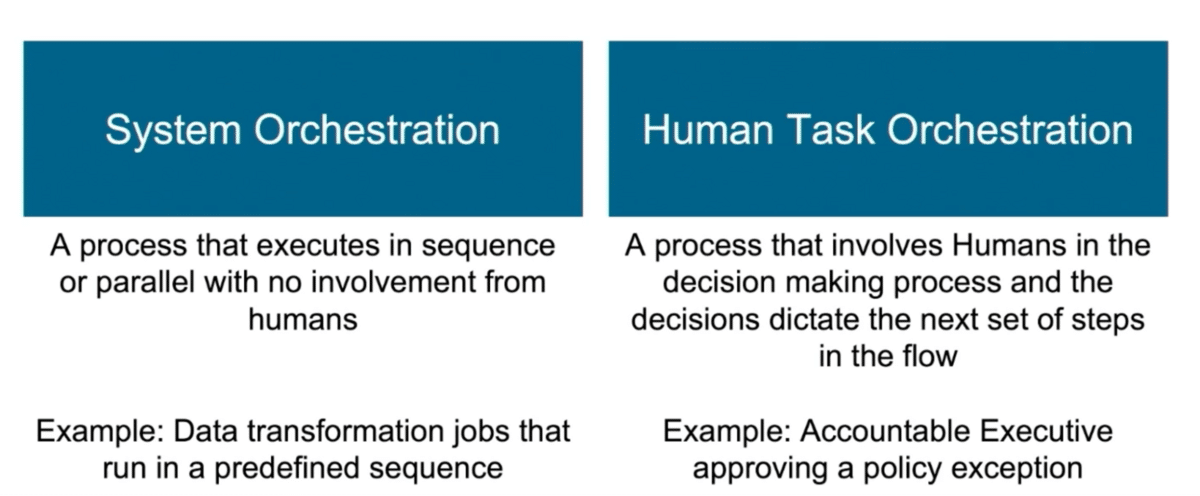
The first is orchestration that enables systems to do their job—often called a system orchestration. There are processes that execute in sequence with no human involvement at all. Then there are a different set of needs where human decision-making is involved, and that they internally had to codify as what they call as human task orchestration. In simple terms, if humans are involved in the decision process where they have to take some actions, what would be the best solution for that? An example might be an executive approving a policy exception.
Obviously, a human task orchestration could trigger a system orchestration based on the need or where you are in the overall process flow. Both of these could interconnect. Capital One’s teams do have a few cloud-native tools that enable them to do system orchestration, but they lacked a standardized, systematic way of managing human task orchestration. Raghavan and Lakshmi shared the high-level architecture and the implementation details of how they solved this.
Requirements for solving the problem
When they started this journey, they did a lot of internal assessment analysis. Should they build something or buy something? They came to the conclusion that it’s more efficient to buy a product than building in-house. Now they had to decide how to choose the best of a lot of products in the market, and used criteria that would determine which product would best fit with Capital One’s culture.
The first was that the product had to be open source. Capital One is an open source first company, so any product that they procure must be open source. And within that, it must have active community participation. They ran into a lot of products that are open source, but in the last year or so, the community participation has been dwindling in many products. Camunda has really strong community participation.
Second, any product they bought must have a roadmap to offer SaaS. They believe that the orchestration engine is a black box to many of the apps that would interact. It would be more valuable for them to use a managed service than a hosted service. There aren’t too many SaaS products as such. But from a target state perspective, when they design a platform, they wanted to make sure that they had a line of sight to a SaaS implementation.
Third, the product must support BPMN and DMN. When Raghavan and Lakshmi’s team did their internal assessment of all the products that they have, they ran into the challenge that there was no clear definition of process attributes among their own products. Rather than defining something internal to a company, they looked at the industry, which has universal standards. They wanted to make sure any product that you evaluate or proceed to go with follows the latest of the standards.
Fourth, is that the product must support multi-tenancy. Capital One is a platform company. They implement platforms to get the best efficiency out of our capabilities. Platforms have to cater to tenants in a platform. So as they set the stage for a platform, they need to think through multi-tenancy day one.
They also looked at some industry-specific capabilities. They didn’t have a good way to understand, across their products, which had processes where the performance issues are, where the gaps are, what are the hotspots. When finding new tooling, they need to make sure these requirements are also met.
Fifth, they are a financial institute. Audit tracking is very critical. They need to know what happened, who did it, why they did it. So they would prefer tooling that would provide these native capabilities.
Finally, the platform they are building needs to connect with other enterprise platforms, as well as other cloud-native services. So they had a heavy emphasis on what connectors they can use as we think through certain products.
They wanted to make sure they had a robust decisioning engine that followed the industry notations as well. Capital One is very specific about event-driven architecture. They have invested heavily in microservices. Event-driven notifications were very important because they wanted the modules within the process to work.
A challenge they had is most of their business and product stakeholders had to depend on engineering organizations to implement some of the simplest of business processes. Therefore, a really important project objective is to enable self-service. They wanted to let the business process modelers do the thing that they’re really good at, rather than having information sent to an engineer, and the engineer translates what the process modeler wants, and then puts it into code.
Human decision-making starts with a task assigned to somebody. And as you can imagine, with an organization that has a lot of business processes, you’re going to get a lot of tasks and it’s not always clear where those tasks are coming from. It was critical not only to have a holistic view of tasks but also to manage them better.
Not only did Capital One have a lot of processes, but those processes often changed along the way. So they wanted to be very sure about how they managed versions across the processes, and ensure they didn’t introduce breaking changes through versions.
How Capital One deployed the solution with Camunda
As Raghavan and Lakshmi evaluated the different deployment options from Camunda, they ended up choosing a remote process engine server. They implemented a service-first architecture.
The architecture has two broad sections.
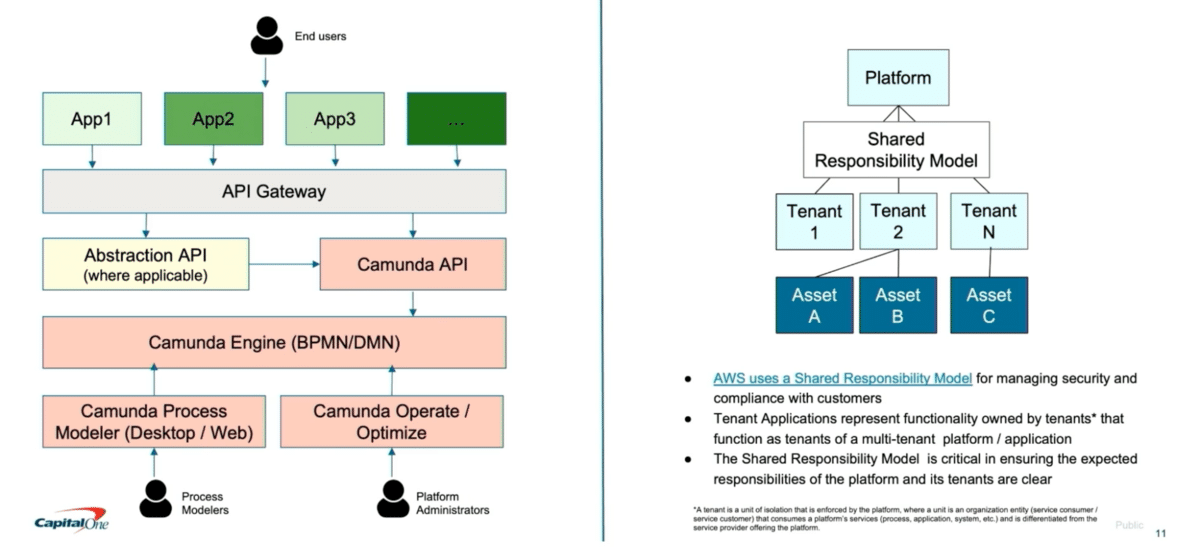
The way they think about the platform is to have the core engine behind a connectable intermediary. So in this case, they exposed the engine’s work through APIs. And they purposely implemented an abstraction layer, which helps with interoperability and portability to any new products or versions going forward. They didn’t want to heavily couple their front-end applications with a particular product, so the abstraction layer helped them best use the back-end process engine. Capital One’s end users are interacting with different applications. The platform does not build those applications. It enables those front-end applications to host their process engine or process.
Interestingly, Capital One’s team hasn’t created abstractions for all their Camunda APIs. They identified which APIs are really needed and enabled an abstraction on top of them, which will help the team as they upgrade Camunda versions. The Capital One team started with Camunda 7 and are intending to move on to Camunda 8.
The other section shows, as Raghavan and Lakshmi noted, their cloud structure. They are on AWS, and AWS has a great framework called Shared Responsibility Model. AWS clearly defines how they treat their tenants, and have defined what are the expectations that a tenant should meet, as well as the expectations that AWS will meet.
Working backward, they have implemented a similar shared responsibility model. So they have a platform team that manages the back-end portion, and then have tenants who are using those platforms benefit from it. A tenant could have assets—in other words, your processes.
The Capital One team implemented this early in 2023, so when they presented on this they were learning along the way. Raghavan noted the great partnership with Camunda—the team ran into a few hiccups, but got them addressed quickly.
How the architecture was implemented
Capital One’s solution architect, Lakshmi Sivaramani, noted that their architecture decision leaned towards implementing a remote command engine. They did it completely on AWS using serverless technologies. They have their tenants who interact with our platform APIs via their UI or APIs. There is also an internal gateway, which acts as a front door for their backend services.
They deployed a streamlined abstraction service using Spring Boot API, which provides a secure and also a purposeful interface for accessing Camunda APIs. As Raghavan mentioned, this implementation not only ensures security, but also paves a path for future migrations, like when we are migrating from Camunda 7 to Camunda 8, or even maturing to the Camunda SaaS model with less disruption to our existing tenants. It also creates a path. to do incremental migrations for our tenants when we are migrating such major versions of Camunda or any other products. At the moment, they are using Camunda version 7, and their Docker image directly sourced from Camunda’s enterprise version and is deployed onto ECS Fargate accompanied by a Postgres SQL.
Observability is a critical aspect for any application and it becomes crucial for platforms. So they take it seriously to have monitoring at all the places. They use a mix of both AWS native-provided services and also some external monitoring solutions plus AWS metrics itself.
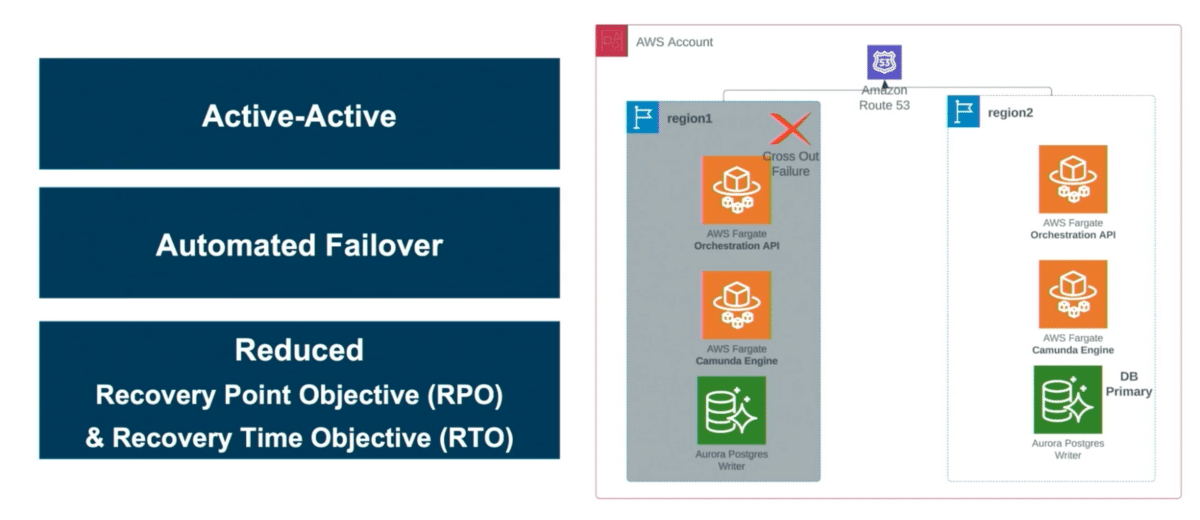
This architecture is highly scalable and resilient because it’s entirely built on AWS and deployed into two regions. AWS defines a region as a large location where they have multiple data centers sitting in one place. We also deployed it into multiple availability zones. An availability zone is equivalent to a data center in case of any disaster. If the worst were to happen, it could be recovered quickly
Everything was implemented using serverless technologies. Their compute layer is sitting on a Fargate instance. ECS Fargate is basically a serverless container management system. The Capital One team chose serverless because of its high availability. Fargate is designed to be highly available across multiple availability zones, ensuring that your application is resilient to any infrastructure failures. It’s also very cost efficient, as they’re billed for their container execution time. And they don’t have to worry about server management at all. AWS takes care of the entire management of it in terms of patching or any other security updates.
On the database side, they use Aurora Postgres. Mainly because of its high performance, it is designed and can deliver almost two to three times more throughput than a traditional Postgres running on similar hardware. It also has auto-scaling capacities for both compute and storage capacities. If you are getting high traffic at some point, AWS will take care of scaling up in both areas. In addition, there is fast failover.
If any of these data centers or AZ goes down for any reason, whether from a disaster, or an infrastructure failure, they are able to quickly spin up in another availability zone, and it’s AWS that manages it within 30 seconds, so there is no application downtime.
The other main reason for using Aurora is global databases. Aurora Postgres supports global databases.They can deploy databases into multi-regions. If any single region were to go down, they are able to replicate and get their application running within a few minutes.
They also deployed everything into a multiple availability zone. AWS’s recommendation as an industry standard is to at least have your application deployed into multiple availability zones. They picked three. Since it’s a platform, we have heavy dependencies from tenants saying that their applications should be highly available and highly resilient to any disasters.
They also used multi-region active-active mode. All of their compute resources are active-active, meaning they take traffic all the time from both regions. We combined it using a geo location based Route 53, meaning a traffic coming from different locations. The traffic will be directed to the nearest location so that we get good performance. And on the database side, Aurora provides only one writer. and can have multiple readers sitting in multiple regions. So in case of any disaster recovery on a backup region for the database, we are able to spin up the writer instance pretty quickly within a few minutes.

Obviously, it all needs to happen with enhanced monitoring. Lakshmi’s team does have a lot of monitoring on the AWS infrastructure itself. They use the CloudWatch metrics, container insights. They also started using AWS X -Ra, which provides distributed tracing from APIs. downstream APIs. They have a mix of external monitoring tools like New Relic, which they use for APM, application performance monitoring on our APIs, and the infrastructure as well.
They have a lot of monitoring on the database, looking for the CPU spikes or any connection spikes.
They do an exercise multiple times a year to see how resilient we are in terms of if there are any disasters. If a disaster happens at the data center level within the AWS region that is automatically taken care by AWS because of the serverless technologies. If a whole region were to fail, since they are maintaining active-active at the compute layer, they don’t have to worry because the traffic will be automatically directed to the active instance. They only need to think about the database, which can be spun up from a replica promoting as a master within a few minutes.
Another good thing they did was automate this entire process using some mechanism without any manual intervention and less human errors. Since they did all this, recovery point of objective and also recovery time objective has been reduced to a few minutes when there is a real disaster.
Lessons the Capital One team learned
Raghavan noted they learned three key lessons during their implementation. They are early in this maturity curve, so they are learning themselves.
The way they structured this was lessons learned before something gets onboarded, lessons learned during onboarding, and then post-onboarding.
The first lesson is one they learned before during their pre-onboarding stage, and that is how to get better at self-service. They thought a lot about how to scale this platform? Many times, when organizations within the company come to them as tenants,they lack knowledge as to what command is, or what these APIs are, how do they make queries, or what are the best practices. It then goes back to a few engineers who are really good at it. But with just a few engineers, the team can’t scale. So to improve scale, they are considering how to establish a center of excellence. That way, we can have a train-the-trainer concept. Their self-serving capability today is heavily dependent on a few individuals. We are trying to put together a framework on self-onboarding. As long as you meet certain criteria, go for it.
We are also implementing some mandatory training, because people come with good intent, but at the same time, they want to avoid the sprawl of processes later down the line. So we are emphasizing mandatory training. You get trained on certain aspects around Camunda, and best practices that we have laid out before you can onboard as a tenant.
The second lesson is around a shared responsibility model. This has been an eye-opener as we went through this journey. What do they expect the tenant to do? And what will the platform do? What data will be stored in our platform versus what data is stored in the applications consuming the platform? They had to be very clear that the platform stores the metadata related to the process, not the data of the apps running the process by itself.
Pretty soon, they found that if they didn’t draw the line, the platform could be seen as a system of record for a lot of data of the apps that are on the front end. Another challenge is access management. Right now, they are handling it in a homegrown manner. But there is an opportunity to adopt native command capability. They would like role-based access. For example, when a tenant makes a call, they are representing a set of users. Do those users have access to do certain activities? Where should that be defined, at a tenant level, which is an app sitting outside the platform making API calls to them? Or do they manage that fine-grained access within the process engine itself? Right now, they’ve defined certain best practices of what is expected from the tenant for access management.
They also had to define their own retention policies because pretty soon we found the data was growing at a greater rate than they anticipated. So they had to fine-tune their service guidelines and retention policies to make sure they didn’t retain any more data than needed.
They also spent time on developing reusable features on the platform. We quickly found that the needs from multiple tenants are similar. So they have put in place a set of libraries for all purposes, a set of reusable process flows that multiple tenants can tap onto. In addition, if they saw periodic connectivity with specific other platforms or systems, they created reusable connectors as well.
The final challenge was around platform configurations. When applications moved to production, strange issues began to pop up. A challenge emerged since they are in a multi-cluster environment. Our timer job executors stuck since they accessed them via API mode. They realized that the issue stemmed from the deployment ideas being memory-driven, causing the applications during cluster restarts or cluster redirects. The solution provided by Camunda was to disable the job executor deployment of the flag on the command engine.
Another issue they discovered in the multi-cluster environment was periodic cockpit login failures. Since the cookie session is not shared across the clusters, it doesn’t know that users are already logged in. So they enabled it again, like application load balancer stickiness that solved the problem. Raghavan and Lakshmi’s team are continuously learning from these models and also getting better at it.
Learn more
You can check out their full presentation at CamundaCon 2023 New York right here.
Start the discussion at forum.camunda.io