

This blog was originally published in 2012 and updated in April 2021 by Nele Uhlemann
In a famous article, Gregor Hohpe describes four strategies for dealing with failures in a business transaction:
- Write-off,
- Retry,
- Compensation
- and Two Phase Commit.
How does BPMN 2.0 and Camunda Platform deal with such problems and exceptions? Here are some experiments I made.
Compensation
In BPMN 2.0 we can model compensation explicitly:
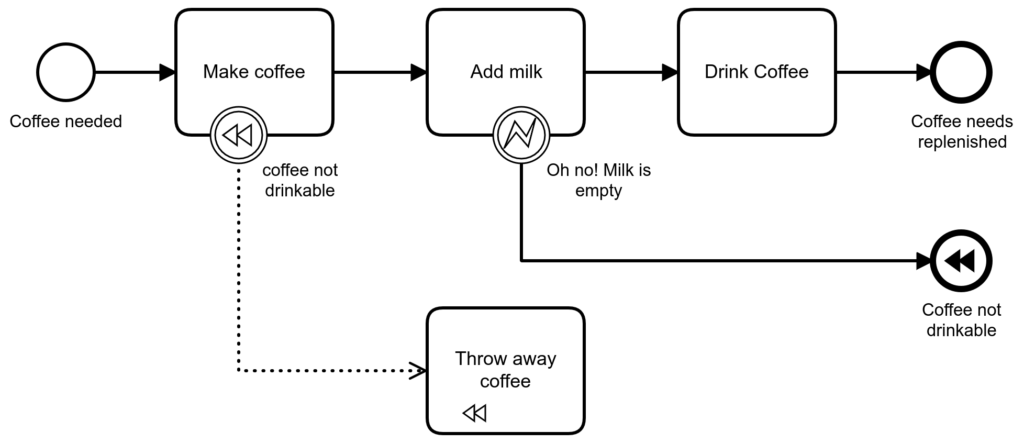
If I detect that I have no milk after making coffee, I throw the coffee away. It is important not to serve coffee without milk, even at the expense of having an unsatisfied customer. By the way, using compensations is a powerful way to roll back Sagas. More about Sagas in the following paragraph.
The Saga Pattern instead of a Two Phase Commit
According to the specification, a BPMN transaction subprocess can be used for 2PC style transactions: “A Transaction is a specialized type of Sub-Process that will have a special behavior that is controlled through a transaction protocol (such as WS-Transaction) (Page 178). I won’t go into the ambiguity of the semantics of a BPMN 2.0 transaction subprocess now. Potentially the transaction sub-process allows distributed, two-phase-commit transactions. Especially with a micro service, Software architecture distributed transactions can become a problem. In general micro service architectures are following an asynchronous communication pattern and distributed transactions are often based on synchronous communication. So this doesn’t fit well together. Using distributed transactions within a micro service architecture, can reduce the overall availability of the system. Moreover, often modern message brokers like Kafka and RabbitMQ and NoSQl databases like MongoDB and Cassandra don’t support distributed transactions. A way to manage data consistency in modern Software architectures is the Saga pattern, which is based on local transactions. The Camunda Engine incorporates the Saga pattern and local transactions. Therefore a transaction subprocess outlines that either everything works or everything fails. It outlines that the tasks inside are somehow closely coupled together. If everything fails inside a transaction subprocess, the cancellation end event does two things: it interrupts the transaction subprocess and it triggers the compensation inside the transaction subprocess to roll back local transactions.
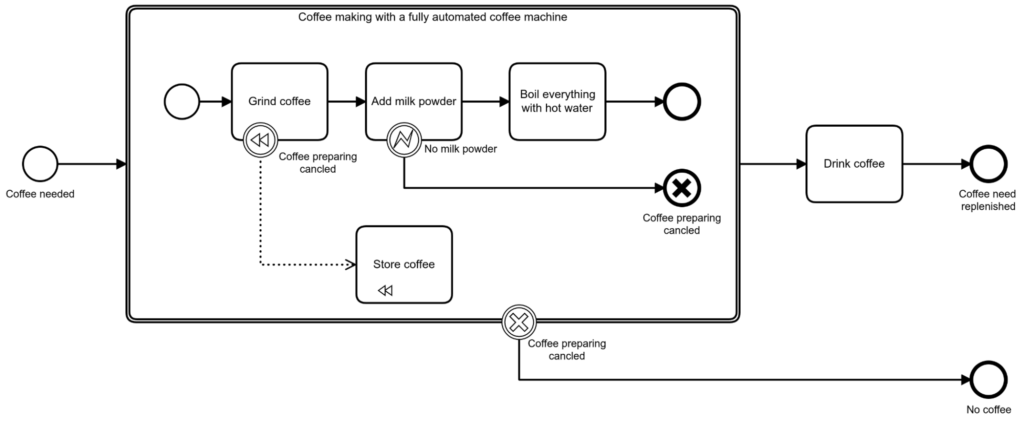
In our real-world analogy, maybe this could be explained by a system where the coffee-making-unit and milk-adding-unit are strongly coupled** and need to reach consensus whether they are able to produce a cappuccino automatically. Assuming that the machine would first grind coffee before it reaches the step to add milk powder, it would need to roll back the coffee grinding if no milk is available. A roll back for grinded coffee is somehow difficult but it still deals with the local transaction that had happened and stores the coffee powder for the next coffee.
If a failure occurs, the customer is still unhappy but we did not waste any resources (we didn’t throw any coffee away). Implementing this might require some more expensive and more complex infrastructure.
Write-off
Write-off means that you detect that there is an error, however you don’t have to / want to handle it now.
So if there is no milk, I simply give up.
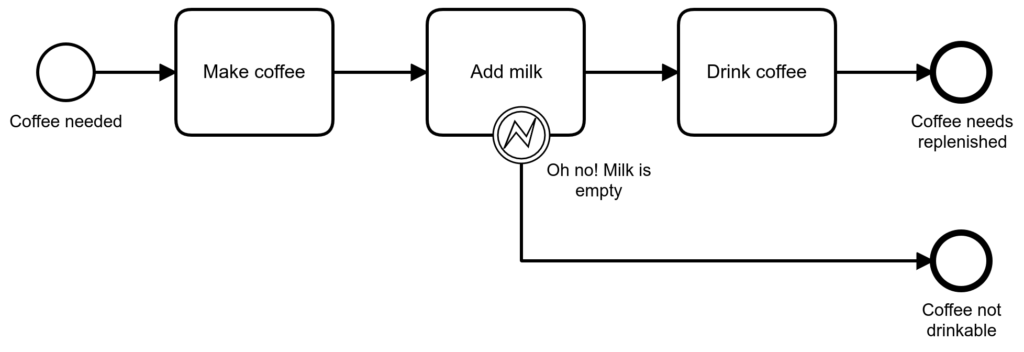
It could also mean that I drink the coffee anyway.

This means that the “error” is there, but I don’t make it explicit in the diagram. I know that there is a possibility that I run out of Milk (actually it happens to me all the time!), but that “error” is handled at a lower level (in the implementation of the “Add Milk” activity). So in this case we do not model the error, BUT: the “Drink Coffee” activity is able to handle both coffee with milk and coffee without milk, and we know it (the awareness is the important part).
Adding milk is optional, but it is still desirable. So even if I cannot do something about it now, I might want to do something about it later:
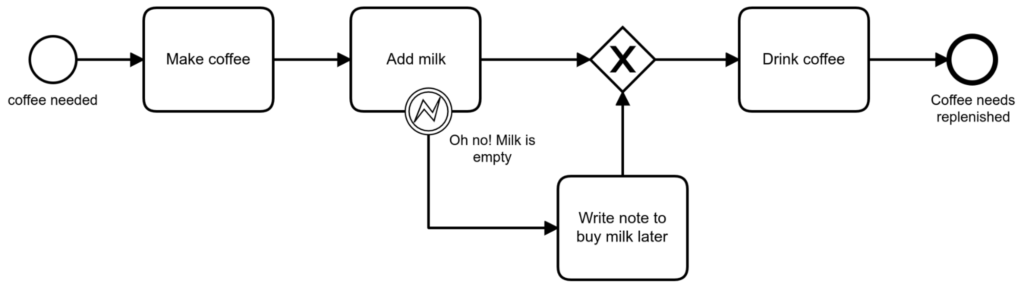
In my opinion this is still a write-off, since I am still drinking this particular cup of coffee without milk.
Retry
Retry can be implemented at different levels.
First, we can of course model the retrying of an activity explicitly:
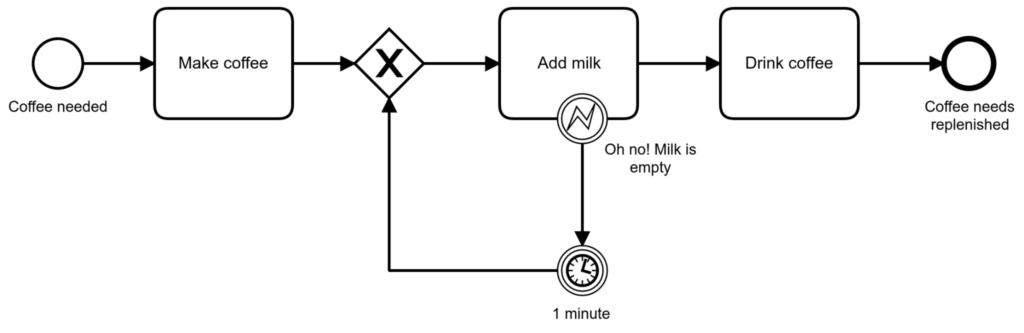
(Ok, granted, maybe the retry doesn’t make much sense in this particular real-world example ???? ). And if we need to do that for all our service tasks we will soon overload the model. Therefore we do not recommend to model the retries of service tasks into your BPMN model.
Second, the retry can be handled by the process engine. The Camunda Platform engine supports the concept of asynchronous continuations: it allows you to define a safe-point before an activity. When reaching the safe-point, the process engine commits its current transaction and releases the thread. In the background a job is created and the job executor takes care of picking the job up. If a job fails, the default behavior of the Camunda Platform engine is to retry every job two times. So in total it tries to execute the task three times in a short time period. The process engine is managing the number of retries and decreases them. Of course in a real life scenario we might like to change the default behavior and decide ourselves how often and in which period of time we want to retry failed service tasks. You can define a global retry strategy on the process engine configuration level or you can define retry strategies on each service task within the BPMN model. The properties panel of the Camunda Modeler offers support to define the retries for your service tasks.
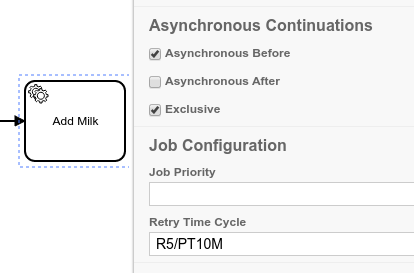
But there is an exception. If you implement your service task as an external task, asynchronous continuation is always true. In the case of an external task, no job is created. Instead an external task instance is generated and put into a list. Here the external task instance waits for the external worker to fetch and lock it. The external task worker then executes the implemented business logic and once completed, communicates back to the engine, so it can continue the execution of the process. With this pattern the decreasing number of retries has to be managed in the code of the external task worker. Instead of completing the task, the external task worker reports a failure, including the remaining numbers of retries as a variable to the process engine. If the number of the retries is greater than 0, the external task instances can be fetched and locked again. If the number of retries equals 0, an incident is created. There is an extension that allows you to still define the initial number of retries and the time frame in the Camunda Modeler for external task clients that are built with the java-client.
In Camunda Cloud service tasks are implemented similar to the external tasks. The job workers fetch and lock available tasks from Camunda Cloud. Therefore the job worker needs to manage the decrease of retries if it can’t succeed.
Third, the retry can be handled by asynchronous / messaging middleware. First, we put a message in a queue. The middleware will then continuously try to deliver the message, until it eventually succeeds.
And finally the retry can be handled at the service level. In this case it is transparent to the service consumer; we simply call the service and wait for a callback response. In the meantime, the service might internally perform retries, maybe using a message queue as well, but we are not aware of it.
I think that the fact that the retry pattern can be implemented at different levels is very interesting and makes it somewhat different from the other patterns:
- This is different in the way compensation is handled. Since the failure of one activity leads to the compensation of another activity, it is best modeled at the process-level. If one service would trigger the compensation of another one directly, we would introduce explicit dependencies between services.
- If the retry number is handled at the service or middleware level, the service invocation must be asynchronous (from the point of view of the process engine). This means that you either need polling or callbacks for retrieving the results and the continuation of the process instance. This actually is the case for Camunda Cloud job workers and for Camunda Platform external task workers.
- If the retry decrease is handled by the Camunda platform process engine, you need to configure asynchronous continuation before the retried activity. This will usually have an influence on threading and transactions.
Furthermore, we can make the following two observations:
- every service that is unavailable is retryable. What I mean: not every service is retryable by its nature (see the cited article by Gregor Hohpe for details). However, if a service call fails because the service is not available (or because the messaging system is unavailable) it is always retryable.
- applying retry sometimes depends on the context of the service invocation. Maybe you want to handle the failure of the same service using retry in one process but using compensation in another process.
From this, I conclude that in general, it is useful and helpful to have some concept of retry at the process-engine level.
However, since implementing retry at the process engine-level needs some concept of “safe-point”, which has an influence on the execution semantics of the process, it is important to understand transaction boundaries of the Camunda Platform engine. Of course adding transaction boundaries changes the process and you might need to adjust your test. To make those transaction boundaries visible in the Modele, there is a Plugin for the modeler.
———-
** interestingly, the article is only available in German Wikipedia