At MINEKO we automate the process for reviewing and validating private and commercial utility bills for tenants. We found that 81% of all utility bills issued in Germany are flawed. So we built a team of legal and automation experts to provide our customers with high quality legal checks on utility bills at a fraction of the costs of a lawyer.
We recently started using Camunda Cloud as part of Camunda’s private beta program. Our intention was to evaluate it for the traditional use case of running business processes, not knowing that it would completely change our thinking of design patterns regarding orchestration of microservices. This post describes our technical architecture in more depth, alongside the reasons we built it and would recommend it.
Our focus is to create great software. We don’t waste time managing servers, containers or boilerplate configuration. Instead we’re “hiring” experts to solve it for us. We integrate a lot of third-party service APIs and refuse to reinvent the wheel. We love using AWS services, which we setup using Infrastructure as Code tools and we’re on the way to a serverless infrastructure. Almost every custom (micro)service at MINEKO runs on AWS Lambda.
With an increasing amount of lambdas, we recognized that we’ll need a way to orchestrate our services. As an example: We generate a pdf file that is sent to the customer as final product. Twelve services are involved in generating the pdf. Services provide data about the customer, the check result, create single pdf pages, merge pages, create a table of contents, set page numbers and so on.
How should our services interact with each other?
Our first approach was to use a kind of orchestrator, e.g. a fat lambda that would control the process and invoke all other lambdas. However, this approach doesn’t work well in a serverless architecture as it’s very likely that you will hit the AWS execution timeout for lambdas. In addition, the orchestrator needs permission to invoke all dependent lambdas, which violates our rule of keeping permissions to a minimum.
Our second approach was to use an event stream to communicate between functions. We had experience with this kind of approach, but not in a serverless environment. During our research on how to setup our architecture around a centered event stream, some questions were raised:
- How should we document the process?
- How much effort is it to keep all 12 services reacting to the correct event?
- How do we enable retries if a service experiences an outage, is not reachable, the connection suffers or other sorts of technical failures occur?
- What will happen on business errors?
- Are we able to maintain this architecture with a small team and increasing amounts of services? We don’t have resources to manage a complicated architecture, analyze tons of log files or use overloaded dashboards.
- How should we manage data consistency and transactions?
In parallel, we’d researched BPMN engines that we planned to use to document and execute our processes. That’s when we discovered Zeebe and, a minute later, the private beta of Camunda Cloud. It was a perfect fit as Camunda Cloud is a managed service of Zeebe, along with the monitoring and management tool Camunda Operate. A deeper look revealed that it’s not just a managed BPMN engine, but it’s a managed platform to orchestrate any kind of services. Additionally we can use BPMN to describe our orchestration.
We started with a simple proof of concept project provided by Bernd Ruecker on GitHub, which worked out well.
Our orchestration approach with Camunda Cloud
After some sandbox testing our first use case was to orchestrate the crucial part of the pdf generation on Camunda Cloud. The BPMN model which describes the process was simple to create.
However, what was challenging was decoupling our services from Camunda Cloud. One important requirement was that our services didn’t know anything about Camunda Cloud. Each of our lambdas comes with its own SQS queue which subscribes to various SNS topics. This architecture enables us to be as flexible as possible, consuming multiple SNS topics (each topic representing a business event) with a managed queuing system in front of the lambdas. Further SQSs can be configured on how to handle retries in case of a failed execution.
With this architecture in mind, the idea was to create an SNS topic where the Camunda Cloud jobs were published to and each Lambda-SQS subscribed to.
Camuna Cloud offers two ways of getting jobs into your system. Either using a poll method (in terms of Zeebe – “job workers”) or by using http requests (available through a hosted http worker). We used both approaches, nevermind that the poll method runs on an serverless on-premises system.
Poll method (Job Worker)
Zeebe’s architecture offers multiple job workers, each registered with a string indicating the type of task this job worker will be responsible for. To keep it simple, we decided to have only one job worker – type “lambda” – where all jobs are polled instead of having individual job workers for each of our lambda functions.
The official Zeebe Node.js sdk comes with native Camunda Cloud support, which kept our implementation effort minimal. To ensure the poll method was as serverless as possible, we decided to run our job worker on AWS Lambda. We set the execution timeout to 15 minutes and created a Cloudwatch event scheduled every 14 minutes to invoke the lambda to make sure we always had an active job worker running. This cost us less than 5€ a month (128MB AWS Lambda, invocation every 15 minutes = ~3000 invocations a month each running 900.000ms).

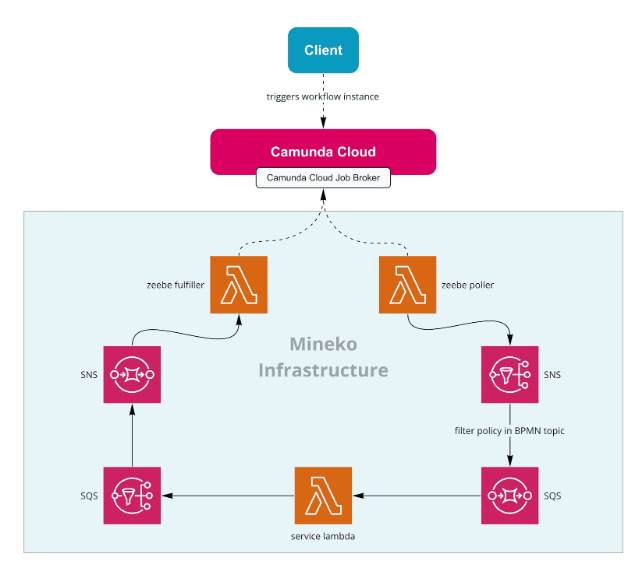
The poll method architecture:
- All jobs for our lambdas are polled by one worker of type lambda
- The lambda name has to be set as job header identifier in BPMN
- Our job worker – zeebe_poller – publishes the job to an SNS topic with the lambda identifier as message attribute lambdaIdentifier
- Each of our lambdas can be invoked from an individual SQS
- Each lambda able to be invoked by BPMN has an SQS subscription to the SNS topic zeebe_jobs with a filter policy set to the message attribute lambdaIdentifier
- The lambda published the result to an SNS topic (zeebe_jobs2complete), from where it is routed to SQS (zeebe_jobs2complete) which then triggers the lambda zeebe_fulfiller which will fulfill (complete, fail or throwError) a job at Camunda Cloud
Our BPMN model (simplified):
With task settings:

We automated the creation of necessary artifacts like SNS, SQS, Lambda or Subscription resources using Terraform. In addition we created a custom Terraform module to create Zeebe-ready lambdas:

You’re welcome to check out the source code here: https://github.com/mineko-io/blog-orchestration-lambdas-using-camunda-cloud
Luckily we already had our own lambda framework in place, which we bundled with every lambda function to automate error tracking, lambda warm-ups, dependency injection and event parsing (which we will announce as an open source project this summer). Because the result of the lambda execution must be published (to be consumed by our zeebe_fulfiller, which will send it to Camunda Cloud) we extended our lambda framework to check if the lambda was invoked from Zeebe and, if so, to publish the result automatically to the corresponding SNS topic.
Simplified usage of the framework:

Simplified abstract of the RuntimeInstance:

We have to point out one pitfall which should remind you to keep an eye on the retry logic.
We didn’t think properly about the retry mechanism of SQS, Lambda and Camunda Cloud. As each of our lambdas has an SQS in front, which has a built-in retry mechanism, we accidentally did a Denial-of-Service attack against Camunda Cloud (btw. sorry for that!).
What happened?- The lambda execution failed
- The error result was published to zeebe_jobs2complete
- Our zeebe_fulfiller failed the job at Camunda Cloud
- Camunda Cloud sent a retry of that job
- In parallel the internal AWS Lambda SQS client invoked the lambda again (with backoff retry strategy)
- Our zeebe_fulfiller had a bug and didn’t decrease the retry count
- Camunda Cloud sent a retry again
- And so on…
Basically we had two queuing systems in place: Camunda Cloud and SQS. We decided to set Camunda Cloud as our master. To do so, we defined a maxReceiveCount property to the redrive policy of the SQS in our Terraform module:

This ensures that SQS will only invoke the lambda once – this shifted the retry responsibility to Camunda Cloud.
HTTP Worker
In addition to the polling, we are also using the Camunda Cloud http worker (available by default) to invoke our lambdas. We have an API Gateway which acts as an SNS sink to the zeebe_jobs topic.


The http method architecture:
- APIGateway endpoint and API key are set as worker variables in the Camunda Cloud Console
- The BPMN task is set to type CAMUNDA-HTTP
- Necessary job headers have to be set (documented here)
- Our endpoint responds with a 201 http status which indicates an asynchronous process to the http workers
- The APIGateway publishes the request to the SNS topic zeebe_jobs
The following steps are defined by the same architecture we’re applying for the poll method.
Currently we are using it for simple tasks which don’t need a lot of variables or custom job headers as the internal http worker comes with some restrictions and increased the configuration in BPMN a bit. But it’s open source and we are able to contribute at least with feature requests ;-). Architecture-wise, we like the http method more and won’t hesitate to switch if the http worker becomes more convenient to use.
For now we will stick to the poll method for the majority of cases as it requires less configuration. And while it might not be the neatest architecture, we find it is worth the 5€/month to have a serverless on-premises component.
Orchestration, retry handling and documentation at once
We found some major benefits using Camunda Cloud which we didn’t get using other systems.
- BPMN is standardized and can be created visually. This is for us a crucial point as we struggled a lot with Amazon State Language using AWS StepFunctions. It’s hard to get a process right looking at a long JSON tail. Using BPMN improves the maintainability of the orchestration. We can show all orchestration models to our colleagues and stakeholders without having problems explaining it. We are also transpiling them into our documentation which is up-to-date even if the orchestration changes.
- Due to the high flexibility we gained orchestrating our services using Camunda Cloud, we are able to easily integrate new services. Not to mention that we benefit from community driven job workers like the DMN worker or the Script worker, which both are incredibly helpful in simplifying your BPMN models.
- Furthermore, Camunda Cloud comes with Camunda Operate, where we can monitor executions and incidents easily without diving into long logs. As well, we hope that Camunda will integrate the collaboration tool Cawemo smoothly into Camunda Cloud along with Camunda Optimize. Looking forward to seeing it.
On our roadmap for 2020 we plan to increase the amount of service orchestrated with Camunda Cloud radically. And regarding the traditional use case of running business processes, we will definitely use Camunda Cloud. We plan to write more blog posts along the lines of “automate business processes using Camunda Cloud” to describe this in more depth.
This guest post was written by Felix Jordan, CTO at MINEKO, who participated in our Camunda Cloud private beta trial. Learn more about MINEKO and the great work they’re doing on the website www.mineko.de and the MINEKO engineering blog: https://medium.com/mineko-engineering
If you’d like to try Camunda Cloud, you’re in luck – we’re now running a public beta version! Learn more and sign up here: https://camunda.com/products/cloud/
Plus, at CamundaCon New York we’ll be announcing the next step on our Camunda Cloud roadmap. Join us in New York City to speak directly with our engineers and learn more about our Cloud offering, as well as connect to the global Camunda Community. 3


