Note (May 2023)
At this time, we ask that you be sure to review the new Tasklist REST API. This API offers the same functionality as the current GraphQL API, but with a more streamlined and efficient way of interacting with our service.
The GraphQL API will be deprecated in the near future. To ensure a smooth transition, we’ll continue to support our GraphQL API for a period of time, giving you an opportunity to migrate to the new REST API version at your own pace. We will provide further details on the timeline and process for this migration soon.
With the switch to Camunda Platform 8, powered by the Zeebe workflow engine, the interface technologies have changed from REST APIs to gRPC and GraphQL. The latter is especially useful when it comes to building your own Tasklist on top of Camunda 8. This is because, in contrast to REST, GraphQL provides a single entry point and works as a query language. This allows you, as a front-end developer, to request the exact data you need. Additionally, it’s not tied to a specific programming language or database technology. GraphQL libraries exist for many programming languages, allowing you to implement an interface backed by your existing code and data objects.
GraphQL powerfully addresses two major problems experienced with REST interfaces: under-fetching and over-fetching. Under-fetching occurs when you need to fetch objects from multiple endpoints for your data, resulting in multiple roundtrips on the network. Over-fetching is the opposite, where the response contains more data than you actually need.
Overall, the new interface technology is promising and definitely worth a shot. In this blog post, we are going to share some query examples for Camunda 8 along with:
How Does GraphQL Work?
GraphQL is a query language for interfaces that uses a server-side runtime for executing these queries. This is why its usage is quite lightweight from a front-end point of view.
First, let’s take a look at the server-side of things. Of course, a schema needs to be defined in order to run queries against the interface. That schema consists of a type, which can be seen as an object or record definition. The object itself can contain multiple fields of different data types. GraphQL types can also relate to each other. This is how the under-fetching issue is addressed. The schema encodes the relationships between entities in a way that allows the GraphQL server to assemble complex responses without multiple roundtrips.
Query and mutation types
Next, let’s define query and mutation types. A query type represents an object to be passed in a query. It communicates two things to the GraphQL server: the query filter for the data to be returned, and the shape of the data object to be returned. This is how over-fetching is addressed. It’s conceptually both the SELECT and WHERE clauses of a SQL query.
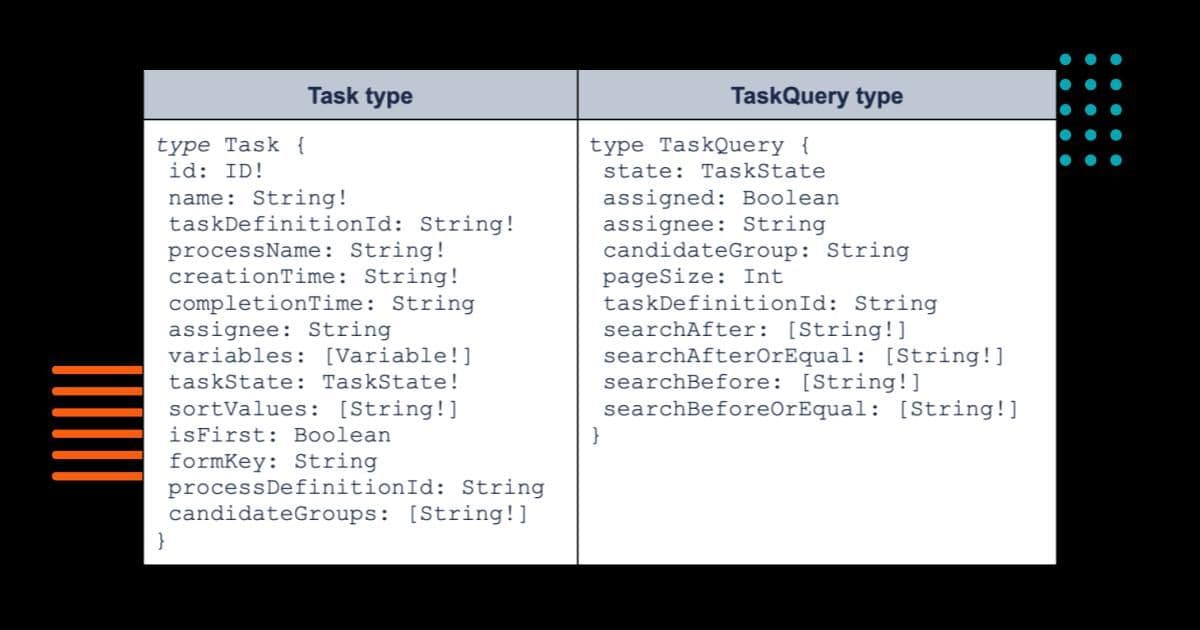
Let’s take a look at a more comprehensive example. For Camunda’s ‘Task type’, which describes user tasks, it looks like this in the GraphQL schema definition — where we also have a ‘TaskQuery type’ for us to query it.

In addition, we need to define the mutations, so we can mutate the task type. In this context, we need ‘mutation types’ for claiming, completing, and unclaiming a task. Look at this example below:
claimTask(
taskId: String!
assignee: String
): Task!Since this schema already exists in the context of Camunda 8, we can now proceed and look at running queries from a user’s point of view. This is usually fairly straightforward since you can easily explore the schema right away in your IDE. Here’s an example of a query to receive the task:

You can see right away that the query has exactly the same shape as the result. This is a specialty of GraphQL. For this request, we’ve set an operation name that contains the query name and keyword. In the second line, we queried our tasks to retrieve the one that fits the given argument. Additionally, we need to specify which variables or objects we want in return. Let’s use its name for simplicity.
Using GraphQL allows us to easily add some further logic such as filtering, pagination, and sorting to our queries. Having the ability to get the exact data you need from the interface is crucial to this language.
Running Your First Query
The easiest way to get started is by booting up the Camunda 8 docker-compose file that is useful for local development purposes. Once this is done, the GraphQL endpoint becomes localhost:8081/graphql. Make sure you have a few running processes and open tasks available to run the query.
Next, we’ll use ‘curl’ for this first example to start independently from the programming language. Before requesting something from GraphQL, we must first authenticate. The command below will return a session identifier that can be used again:
curl -v -XPOST 'http://localhost:8081/api/login?username=demo&password=demo'Now, it’s time to run an actual query. Make sure to check out our documentation for the GraphQL API. This comes in handy when developing further queries. For our first example, we want to get all open tasks and their names. The curl command and query to send it to the Tasklist GraphQL endpoint will be:
curl -b "TASKLIST-SESSION=<Session-ID>" -X POST -H "Content-Type: application/json" -d '{"query": "{tasks(query:{}){name}}"}' http://localhost:8081/graphqlIn the table below, you can once again see the similarity between the request and response.

Mutating Data via GraphQL
Besides reading and fetching data from an API, we want to be able to modify server-side data as well. That’s where mutations come in handy. In GraphQL, you can mutate data with any query. Nevertheless, you should try to establish a convention that you only use for explicit mutations to cause a write operation.
The Camunda Tasklist API provides mutations for claiming, completing, and unclaiming tasks as well as deleting process instances. For this example, we are going to use GraphQL that can be seen as an IDE for that interface technology. This makes writing queries way easier than with curl. Make sure you’ve edited the HTTP Headers accordingly before using this tool.

In the picture below, you can see the mutation query to claim a user task with a given ‘taskId’. As a result, we can see that claiming the task was successful and we have received its name and ID as specified.

There’s More to Come
Now, you’re more familiar with GraphQL, aware of its benefits, and able to run queries and mutations against Camunda’s Tasklist API. The next step on your GraphQL journey is to implement a first custom Tasklist relying on GraphQL in Camunda Platform 8. Get started and sign up for a free, full-fledged Camunda Platform 8 SaaS trial.
Of course, you can count on support from our developer advocates along the way. I’ll soon be releasing some live coding videos about this topic with Josh Wulf. Stay tuned!


