Testing distributed systems is hard. In this article, we explain how we test and identify hard-to-find critical bugs in Zeebe, the workflow engine powering Camunda Platform 8, using property-based testing.
Losing data is one of the worst bugs that can happen in a system. The bug Cannot truncate committed index was something like this. The system was trying to delete already committed data. Fortunately, this was not in a production system. I started investigating it and no matter how hard I tried, I was not able to come up with a situation that could lead to this state. To reproduce the bug, the concurrent interactions between the nodes must happen in a specific order. Since it is not possible to control thread scheduling or network, it was quite difficult to reproduce it. During my investigation, it happened once or twice again, but it did not give any new information on what caused this bug.
In the end, we were able to use property-based testing to identify hard-to-find critical bugs in Zeebe, the workflow and decision engine that powers Camunda Platform 8. In this article, we wanted to share our methods so that you can understand how we keep Camunda Platform robust and to hopefully help you uncover similar bugs in your own development.
Testing distributed systems is hard
Zeebe has an inbuilt data management system that stores and replicates data related to process orchestration. At the core of the data management is Raft, which is the replication and consensus protocol. Any bug in the Raft module can lead to critical bugs that result in partial or full data loss, or partial or full system unavailability. Raft is a well known protocol and widely used, which has also been theoretically proven to be correct. What is left is to verify if the implementation is correct.

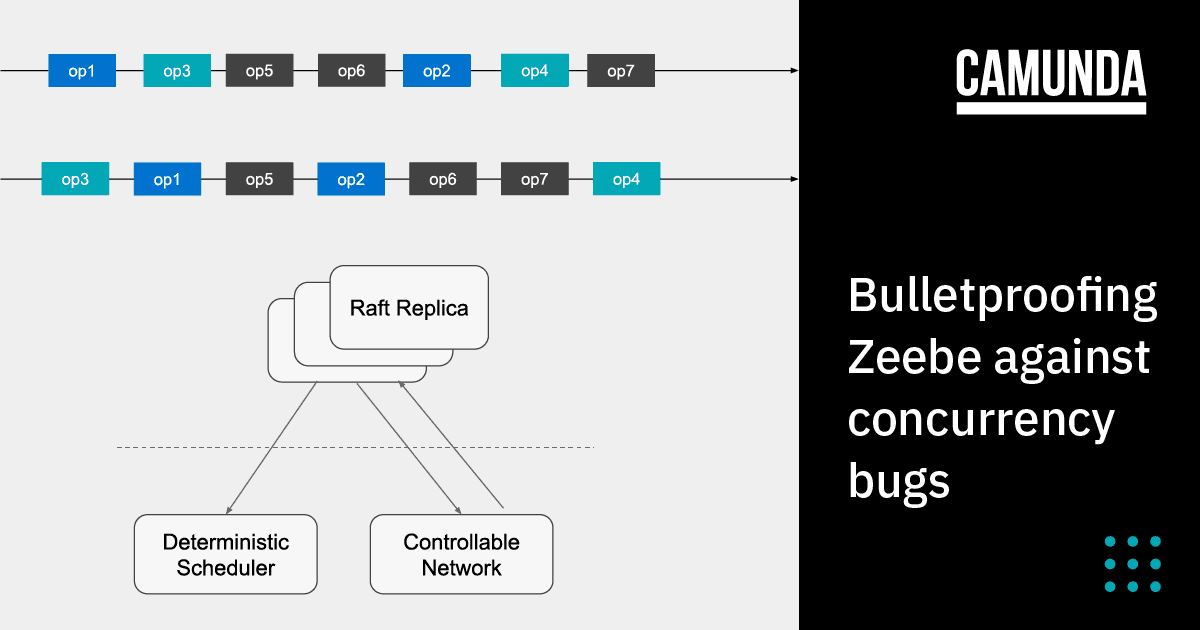
Each Raft replica is a single threaded process and executes operation sequentially, while interacting with other replicas by sending or receiving messages. Because each replica processes instructions concurrently, there are multiple possible execution orders. Each of the execution orders can potentially result in a different state.

Additionally, failures like message loss, delays, or restarts of replicas impact the execution of the system. Each of these execution orders comes with its own edge cases. The bug we observed is an example of such a scenario. It is nearly impossible to write unit tests to cover all possible cases, but we always strive for increased test coverage and improving the confidence in the code we deliver.
Property-based testing
Unlike a normal unit test, a property-based test does not test using a specific input. A function, program, or a system under test is executed using a randomly generated input. Then, a property is verified. The test can be run with any random input but the property to verify remains the same. This helps cover more possible edge cases than what we can cover using a fixed set of inputs.
We used this idea to verify different possible execution orders of the Raft protocol implementation. We applied property-based testing to Raft as follows:
- Generate a random execution order.
- Execute each step of the execution order.
- After each step, verify the properties are not violated.
Test setup
We use jqwik as the test engine. It is a property-based testing framework that enables reproducible test execution using seeds. However, we still have to ensure our executions are deterministic and we must decide which properties to verify.
Properties
First, we identified what properties to verify. We categorized the properties into two: safety and liveness.
Safety properties
Safety properties ensure “no bad things happen.” Raft paper already defines a set of such properties. We picked the following properties to test:
- Election safety: At most one leader can be elected in a given term.
- Log matching: If two logs contain an entry with the same index and term, the logs are identical in all entries up through the given index.
Liveness properties
Liveness properties ensure “eventually good things happen.” This is a bit tricky, because in a distributed system failures can happen at any time and the system is guaranteed to make progress only in specific cases. To narrow down the scope, we define the liveness properties as follows:
- In case of no failures, eventually a leader is elected.
- In case of no failures, eventually all records are committed and replicated to all replicas.
Deterministic scheduling
It is important that we can test a specific execution order and that the result is reproducible. For that, the testing infrastructure provides a deterministic scheduler and a controllable network, which is injected into the Raft replicas under test. The testing infrastructure decides when a replica processes an instruction or when a message is delivered. Besides, the clock is also controlled by it so that the timeouts and delays are also deterministically reproducible. The controlled network also allows us to simulate network partition by dropping undelivered messages.

Input generation
The input for the property-based test is a sequence of “operations.” These operations define an execution order that can happen in a real production environment. Since each Raft server is single-threaded, we define one step as a single task scheduled on the thread. We ignore the possible concurrency at the level of CPU instruction, but rather focus on the concurrency possible due to interactions between each Raft server via messages. The set of operations include the normal Raft operations such as “Append a record” (write an entry to the log), “Take a snapshot and compact” (see Further Reading to learn about log compaction in Raft), and “Receive a message”. These operations are submitted to the deterministic scheduler and are executed when they are instructed to do so. Since some of the actions are triggered by timeout, updating the clock is also one of the operations. Additionally, we simulate failures using operations such as “Drop a message,” “Restart a node,” or “Update clock (by election timeout).”
In summary, we have the following operations:
- Append a record
- Take snapshot and compact
- Receive a message
- Execute one task
- Update clock by x ticks
- Drop a message
- Restart a replica
The input to the test is a list of operations randomly generated from the above set. Each operation is paired with one Raft replica on which the operation will be applied.
Putting it all together
The test for safety is as follows. The code illustrated here is a simplified version of the actual code, but it gives you a clear idea how we apply the property-based testing concept. The test executes an operation iteratively on each member. After each step, it verifies if the safety property is satisfied.
@Property(tries=10)
void consistencyTest(
@ForAll("raftOperations") final List<RaftOperation> raftOperations,
@ForAll("raftMembers") final List<MemberId> raftMembers) {
final var memberIter = raftMembers.iterator();
for (final RaftOperation operation : raftOperations) {
final MemberId member = memberIter.next();
operation.run(raftContexts, member);
verifyAtMostOneLeaderExists();
verifyAllLogsEqual();
}
}The liveness test is similar to the consistency test, but after execution of the input operations, it executes a few more steps without any failures like message loss or restarts. This is required so the members can recover from any failures that were injected as part of the input operations. When there are no failures, eventually all liveness properties must be satisfied.
@Property(tries=10)
void livenessTest(
@ForAll("raftOperations") final List<RaftOperation> raftOperations,
@ForAll("raftMembers") final List<MemberId> raftMembers) {
final var memberIter = raftMembers.iterator();
for (final RaftOperation operation : raftOperations) {
final MemberId member = memberIter.next();
operation.run(raftContexts, member);
}
// when - no more message loss or restarts
while (numStepsWithoutFailures-- > 0) {
runAllScheduledTasks();
processAllMessage();
tickHeartbeatTimeout(); // update clock
}
// then - verify liveness properties
verifyThatALeaderExists();
verifyAllLogEntriesAreReplicatedToAllMembersAndCommitted();
}Because it takes a long time to run all possible executions, we run the test using a fixed number of tries. For each try, the test receives a different set of input generated from a random seed. The test is run with every build that runs on the CI, with every pull request and every commit to the main branch. Over time, it would cover a large set of inputs. We hoped this would catch bugs that would happen quite rarely, and it did.
Bugs
Using property-based tests we reproduced bugs reported by customers and also found new bugs that are difficult to debug or reproduce.
When we first introduced property-based tests, we were only verifying safety properties. The following bugs were found immediately after adding these tests.
Issue #5360 – A stepdown might result in inconsistent log in the old leader. This was a critical bug that leads to inconsistency in the data.
Issue #5356 – Raft elects two leaders at the same term. This was another critical bug that violates basic Raft correctness property that can lead to inconsistent state or even data loss.
We added liveness properties to the test while trying to reproduce a customer reported bug. With the new tests, we were able to reproduce the bug as well as find new ones, such as Issue #8324 , Issue #10180, #Issue 10202, Issue #10545. Being able to deterministically reproduce them also helped us to root cause and fix them fast.
Conclusion
It is difficult to find hidden bugs related to concurrency because there are several possible executions and each execution could lead to its own edge cases and bugs. With the help of property-based testing frameworks, we built a testing infrastructure that covered several possible executions of Raft implementation. Property-based tests generate a random input which corresponds to one of the many possible executions, and verify pre-defined properties are met. If not, we can reproduce the failure by re-running the test with the same seed. This helps us to find the root cause and fix bugs fast. Since it is not possible to cover all possible inputs, each run of the test covers a random subset of the input. Over time, it would cover a significant number of scenarios. Though we cannot be sure it covers all scenarios, in our experience this was already very valuable.
Property-based tests are just one of the many tools we use in testing our system. It has been incredibly useful for us in uncovering hard to find critical bugs. Continuously running these tests has improved our confidence in the system. So far, this technique is only used in testing Raft implementation and in the process engine to test randomly generated process models. It is also possible to apply this in other modules where concurrent interactions makes testing difficult.
Further reading
- Overview of Raft consensus algorithm https://raft.github.io/
- Raft paper In search of an Understandable consensus algorithm
- Property based testing https://jqwik.net/property-based-testing.html


