Camunda recently added hot backup support in version 8.2. Hot backups are taken while the system is still running, which means there is no downtime. This is in contrast to cold backups, which require the system to be stopped.
Backups are necessary to help safeguard against data loss in the event of failures or disasters. Particularly in systems like Zeebe, which needs to be highly available, the ability to create hot backups is invaluable due to its minimal operational disruption.
Implementing hot backups, however, presents greater complexity compared to cold backups. One of the challenges is to ensure that data in the backup is consistent. This is so because the data is being updated while we are taking a backup. Another challenge is the need to minimize the impact of the backup on the performance of the cluster. The backup process must be able to run without interrupting any ongoing processes.
In this blog, we’ll take a deep dive into how hot backups are implemented in Zeebe. If you are looking for a broader introduction to hot backups in Camunda, you can find an informative presentation by Ole Schoenburg at the Camunda Community Summit 2023.
Why are hot backups complex?
In a distributed system, data is typically spread across multiple nodes. The backup process must ensure that the backup consists of a consistent view of the data from all these nodes. This requires some coordination among the parties involved.
Let us consider the scenario within Zeebe. Zeebe consists of several partitions. For simplicity, let us ignore replication for now. Each partition stores data exclusive to it. The backup of Zeebe should contain backup of data in all partitions.
Each partition processes process instances independently of other partitions. However, there are some cases where the partitions have to interact with each other, for example during message correlation.

The above figure shows Partition 1 processing a process instance that is waiting for a message from an external service. The messages are sent to a specific partition based on the correlation key of the message. (Read more about Message Correlation in the Camunda documentation). In this case, let’s assume that the message will be sent to Partition 2. Partition 1 sends a request to Partition 2 to notify that it is waiting for the message. Once Partition 2 receives the message, it will send it to Partition 1 and the process instance can then advance to the next step.
Now consider we are taking backups during this time without any special coordination. We take backup of each partition independently. What happens then?

The above figure shows that Partition 2 took a backup before receiving a request from Partition 1. Partition 1 took a backup after receiving an acknowledgment from Partition 2. If we restore from this backup, Partition 1 will be waiting for the message forever because Partition 2 does not know that Partition 1 is waiting for it. Partition 1 will not retry the message because it has already received the acknowledgment from Partition 2. This is inconsistent with the expected behavior, and a user would not be able to understand why the process instance is stuck even after resending the message.
Inconsistent backup can occur in several other cases. For example, when Partition 1 takes backup before sending the “msg”, and Partition 2 takes backup after sending the acknowledgment to Partition 1. One way to handle this is to fix the inconsistency after restoring from the backup. However, this would require identifying each possible inconsistency and finding a fix for each individual case. This may not be feasible in all cases. Even if it is feasible, it would be a time-consuming, complex, and error-prone process. It is more desirable to find a solution that prevents inconsistencies from occurring in the first place.
How Zeebe performs hot backups
The backup algorithm of Zeebe is inspired by A Distributed Domino-effect free Recovery Algorithm and An Index-based Checkpointing Algorithm. These algorithms define how to take a global checkpoint of a distributed system via a lazy coordination among participating processes.
A local checkpoint refers to a state of the process at a particular point in time. A global checkpoint is a set of local checkpoints from all processes in the system. To get a consistent global checkpoint, each process takes local checkpoints at its own pace, and then piggybacks its local checkpoint’s information in every message sent to other processes. When the other process receives this message, it is forced to take a checkpoint that forms a consistent global checkpoint. When the state of the local checkpoints of a global checkpoint is saved to a stable storage, they become a backup of the system.
Following this algorithm, the backup process of Zeebe uses very minimal coordination among the partitions. Each partition marks its local checkpoint and saves the backup to an external storage independently of the other partition. Here a checkpoint is a logical concept that represents the state of the system at a particular point in time. The backup refers to the physical data corresponding to the checkpoint that is saved to a stable storage.
Each checkpoint within a partition has a unique ID. The backups of all partitions with the same checkpoint ID form a consistent backup of Zeebe.
The backup process with in a partition is as follows:
- Each partition keeps track of its last checkpoint ID.
- Whenever checkpoint ID is updated to a higher value, a new backup of the partition is taken. The backup contains the state of the partition until this point.
The checkpoint ID can be updated in two ways.
- Via inter-partition communication
- When a partition sends a message to another partition, it piggybacks its checkpoint ID.
- When a partition receives a message with a higher checkpoint ID, it updates the local checkpoint ID to the new one. The received message is processed only afterwards, thus it is not part of the backup.
- Via external trigger
- An external service or a user can trigger a backup by incrementing the checkpoint ID.
Here, the partitions don’t use any expensive synchronization mechanism to coordinate taking backups. Instead, it relies on lazy coordination by piggybacking the current checkpointId to force another partition to take a backup. Although there is no explicit synchronization between the partitions, this process still ensures that the backups are consistent. The details are not discussed here, but the proof of its correctness can be found in the linked papers.
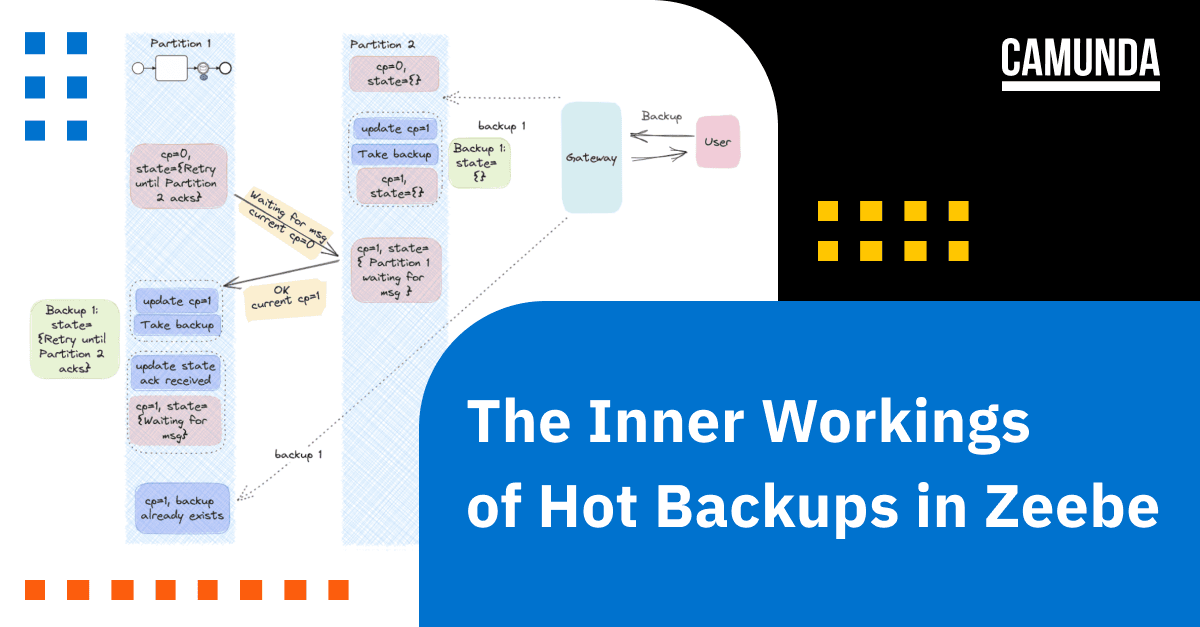
Let’s see how this process prevents the inconsistent backup observed before.

Here each partition starts with the checkpoint ID (CP) 0. A user can trigger a backup by sending a request to Zeebe. The gateway sends this request to all partitions, which starts the backup process in each partition.
When Partition 2 receives the backup request, it updates CP to 1 and takes the backup. At this point, Partition 2’s backup contains an empty state, as it has not received the message from Partition 1 yet.
When Partition 1 sends the request to Partition 2, Partition 1’s CP is still 0 because it has not yet received the backup request. When Partition 2 receives this request, it piggybacks the new CP=1 with the acknowledgement. When Partition 1 receives the acknowledgement, it sees that there is a new CP, triggers a new backup before processing the acknowledgment. At this point, Partition 1’s backup contains a state that shows it has to send the request to Partition 1.
When you restore from this backup, Partition 2 doesn’t know Partition 1 is waiting for the message, and Partition 1 knows that it has to send the request to Partition 2. Thus both partitions are in a consistent state. Partition 1 will resend the request to Partition 2, and Partition 1 will forward the message when it receives one. The process instance can make progress when the user sends the message after restoring.
Putting the pieces together
Let’s get an overview of how everything converges within Zeebe.

When a user requests a backup, the gateway sends the request to all partitions. Each partition then creates a “checkpoint:create” record in its logstream. The checkpoint ID is the same as the backup ID. A “checkpoint:create” record is also written when receiving a request from a remote partition, if the local checkpoint ID is different from the remote partition’s checkpoint ID.
When a partition processes a “checkpoint:create” record, it sends an asynchronous request to the BackupManager. The BackupManager then begins taking the backup in the background. The BackupManager collects the snapshot and the log segments that need to be included in the backup. Once these have been collected, the backup is saved to the configured backup store.
The “checkpoint:create” record marks the checkpoint. That means, the backup should only contain the records up to this record. However, since the backup is taken asynchronously, the log segments may contain events that are beyond the checkpoint record. To reduce the overhead during backup, we also include these events in the backup. This is then repaired during the restore process by deleting all records after the checkpoint record. The restore process is the process of copying the backup data to a cluster to recover from a disaster.
This is a trade-off between performance and resource usage during normal operation, and the complexity of restore. Because backups are expected to be scheduled frequently, it is important for them to have minimal impact on the system’s normal operations. Restoring is only expected to happen rarely, so it is acceptable for it to be more complex.
Conclusion
Hot backups are crucial for maintaining the reliability and resilience of Zeebe. Nonetheless, hot backups are complex because of the coordination required among the participating members to ensure a consistent view of the state. In Zeebe, this challenge has been addressed through the implementation of an index-based checkpointing algorithm.This new feature enables taking backups without disrupting operations, ensuring data protection and business continuity.
Our discussion has focused solely on the hot backup process within Zeebe. The Camunda platform comprises various other components such as Operate, Tasklist, and Optimize, all of which collaborate on the same dataset. Consequently, ensuring consistent backups across these components is equally critical. You can find detailed documentation for this process in the Camunda documentation.


